

Tabular datasets remain fundamental to numerous critical applications across sectors such as finance, healthcare, energy, and manufacturing. Unlike domains dominated by images or extensive text, these fields rely heavily on structured data organized in rows and columns. Expanding capabilities in this domain, TabPFN-2.5 emerges as a cutting-edge tabular foundation model that significantly enhances in-context learning, now accommodating up to 50,000 samples and 2,000 features-all while maintaining a training-free, streamlined workflow.

Evolution from TabPFN to TabPFN-2.5: Expanding the Horizons of Tabular Learning
The original TabPFN demonstrated that transformer architectures could emulate Bayesian inference on synthetic tabular datasets, effectively managing up to 1,000 samples with purely numerical features. Building on this foundation, TabPFNv2 introduced robustness to real-world complexities by supporting categorical variables, handling missing data, and mitigating outliers, scaling up to 10,000 samples and 500 features.
TabPFN-2.5 represents a substantial leap forward, designed to efficiently process datasets with as many as 50,000 rows and 2,000 columns-multiplying the data capacity by approximately 20 times compared to its predecessor. This model is accessible via the tabpfn Python package and through a dedicated API, facilitating seamless integration into existing workflows.
| Feature | TabPFN (v1) | TabPFNv2 | TabPFN-2.5 |
|---|---|---|---|
| Maximum Recommended Rows | 1,000 | 10,000 | 50,000 |
| Maximum Recommended Features | 100 | 500 | 2,000 |
| Supported Data Types | Numerical Only | Mixed (Numerical & Categorical) | Mixed (Numerical & Categorical) |
Revolutionizing Tabular Predictions with In-Context Learning
TabPFN-2.5 continues the innovative approach of prior data-fitted networks by leveraging a transformer-based architecture that performs in-context learning. During training, the model undergoes meta-learning on a vast array of synthetic tabular tasks, enabling it to internalize diverse data patterns and relationships. At inference, users provide both the training dataset (features and labels) and the test samples simultaneously. The model then executes a single forward pass to generate predictions, eliminating the need for iterative gradient updates or hyperparameter tuning specific to each dataset.


Performance Benchmarks: Dominating TabArena and RealCause Datasets
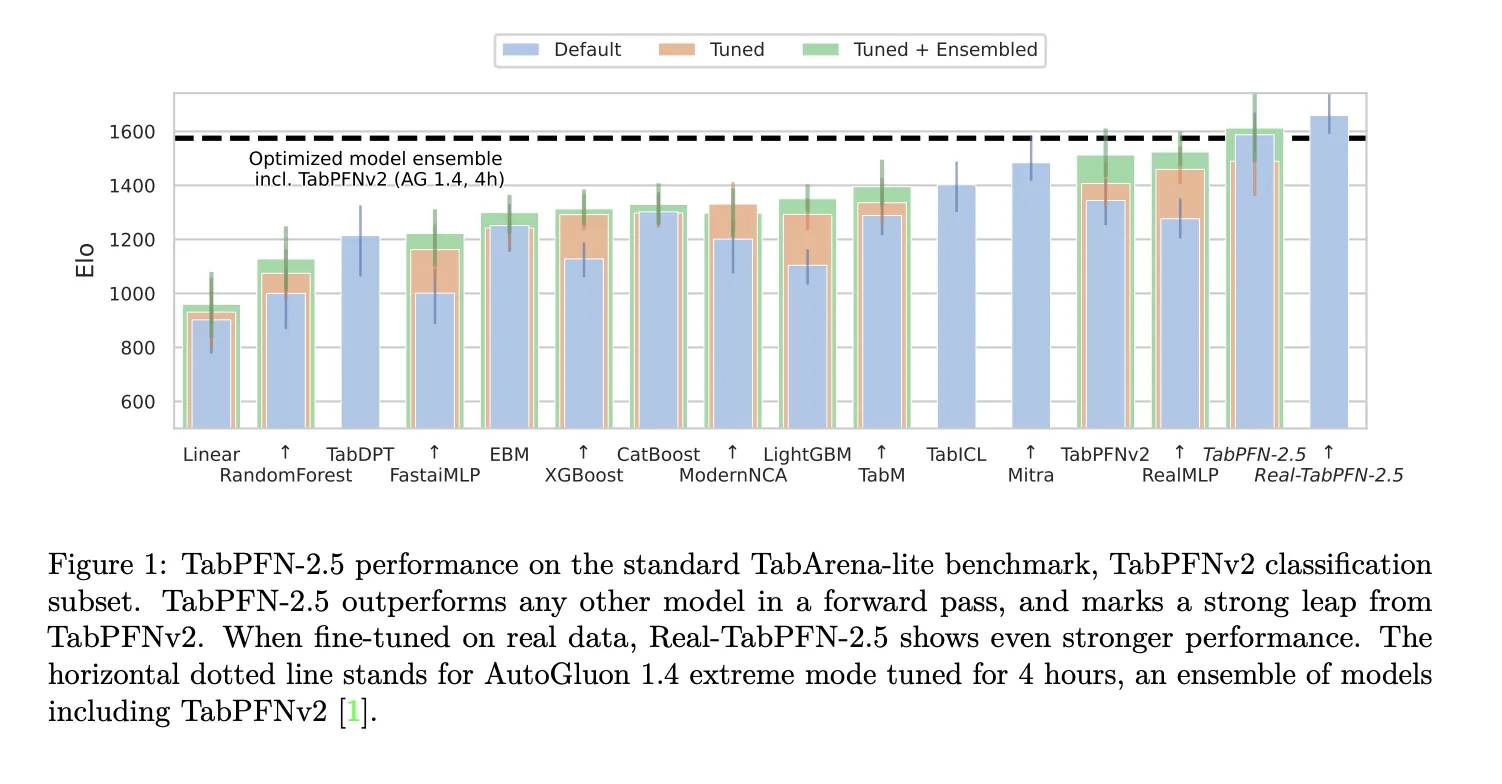
Evaluations on the TabArena Lite benchmark, which includes medium-scale datasets with up to 10,000 samples and 500 features, reveal that TabPFN-2.5 surpasses all competing models in a single forward pass. Its variant, Real-TabPFN-2.5, which undergoes fine-tuning on authentic datasets, further extends this performance advantage. For context, AutoGluon 1.4 in its extreme mode-an ensemble method fine-tuned over four hours and incorporating TabPFNv2-is used as a baseline.
On larger, industry-standard benchmarks featuring up to 50,000 data points and 2,000 features, TabPFN-2.5 consistently outperforms well-established tree-based algorithms like XGBoost and CatBoost. Moreover, it achieves accuracy on par with AutoGluon 1.4’s comprehensive, time-intensive ensemble, underscoring its efficiency and effectiveness.
Architectural Innovations and Training Methodology
The architecture of TabPFN-2.5 builds upon the foundation laid by TabPFNv2, employing 18 to 24 layers of alternating attention mechanisms. This design alternates focus between the sample dimension and the feature dimension, ensuring permutation invariance-meaning the model’s predictions remain consistent regardless of the order of rows or columns. This property is crucial for tabular data, where the arrangement of data points and features does not inherently convey meaning.
Training leverages synthetic tabular datasets generated from diverse priors over functions and data distributions, enabling robust meta-learning. The Real-TabPFN-2.5 variant extends this by continuing pretraining on curated real-world datasets sourced from platforms like OpenML and Kaggle, carefully excluding any overlap with evaluation benchmarks to maintain unbiased assessment.
Summary of Key Advantages
- TabPFN-2.5 dramatically scales tabular transformer models to handle datasets with up to 50,000 samples and 2,000 features, all while preserving a single forward pass inference without the need for tuning.
- It is trained on a broad spectrum of synthetic tabular tasks and validated on benchmarks such as TabArena and RealCause, where it outperforms traditional tree-based models and rivals state-of-the-art ensembles like AutoGluon 1.4.
- The model’s alternating attention transformer architecture ensures permutation invariance and enables efficient in-context learning without dataset-specific training.
- A dedicated distillation process converts TabPFN-2.5 into compact multi-layer perceptron (MLP) or tree ensemble models, retaining most of the original accuracy while significantly reducing latency and facilitating easy deployment within existing tabular data pipelines.
Final Thoughts
TabPFN-2.5 marks a pivotal advancement in tabular machine learning by transforming the traditionally complex and time-consuming processes of model selection and hyperparameter tuning into a straightforward, single-pass operation. By integrating synthetic meta-training, real-world fine-tuning, and an effective distillation mechanism, it offers a practical and scalable solution for real-world tabular challenges. Its open licensing and enterprise-ready design further position it as a valuable tool for organizations seeking efficient, high-performance tabular data modeling.






{kind=link}