
Since the release of GPT-2 in 2019, OpenAI had not made any open-weight language models publicly available-until now. In a surprising move, they introduced two new models: gpt-oss-120b and its smaller counterpart, gpt-oss-20b.
Curious about their real-world capabilities, we subjected both models to rigorous evaluation using our open-source workflow optimization tool, syftr. This framework assesses models under various scenarios, balancing speed, cost, and accuracy, and incorporates OpenAI’s novel “thinking effort” parameter.
While intuitively, increasing “thinking effort” should enhance response quality, our findings reveal that this is not always the case.
Benchmarking GPT-OSS Models Against Leading Open-Weight Alternatives
Rather than limiting our comparison to GPT-OSS variants alone, we expanded our analysis to include several prominent open-weight models:
- qwen3-235b-a22b
- glm-4.5-air
- nemotron-super-49b
- qwen3-30b-a3b
- gemma3-27b-it
- phi-4-multimodal-instruct
To explore the impact of the “thinking effort” setting, each GPT-OSS model was tested across three levels: low, medium, and high, resulting in six distinct configurations:
- gpt-oss-120b-low / medium / high
- gpt-oss-20b-low / medium / high
Our evaluation spanned five retrieval-augmented generation (RAG) and agent modes, 16 embedding models, and diverse workflow configurations. Model outputs were assessed using GPT-4o-mini, with answers benchmarked against verified ground truths.
Testing was conducted on four datasets representing varied challenges:
- FinanceBench (financial reasoning)
- HotpotQA (multi-hop question answering)
- MultihopRAG (retrieval-augmented reasoning)
- PhantomWiki (synthetic Q&A pairs)
We optimized workflows twice-once prioritizing accuracy and latency, and once focusing on accuracy and cost-to capture the critical tradeoffs relevant to practical deployments.
Balancing Speed, Expense, and Precision: Key Insights
Our optimization experiments revealed some unexpected trends:
- GPT-OSS 20b with low thinking effort: This configuration consistently delivered fast, cost-effective, and reliable results. It frequently appeared on the Pareto frontier, making it an excellent default choice for most applications that do not require scientific-level precision. Users benefit from quicker responses and reduced expenses compared to higher thinking effort settings.
- GPT-OSS 120b at medium thinking effort: Best suited for complex tasks demanding deeper analytical reasoning, such as financial benchmarks. This setup is ideal when accuracy outweighs cost considerations.
- GPT-OSS 120b with high thinking effort: Generally costly and seldom justified by performance gains. Reserve this mode for rare edge cases where other configurations fail to meet requirements.


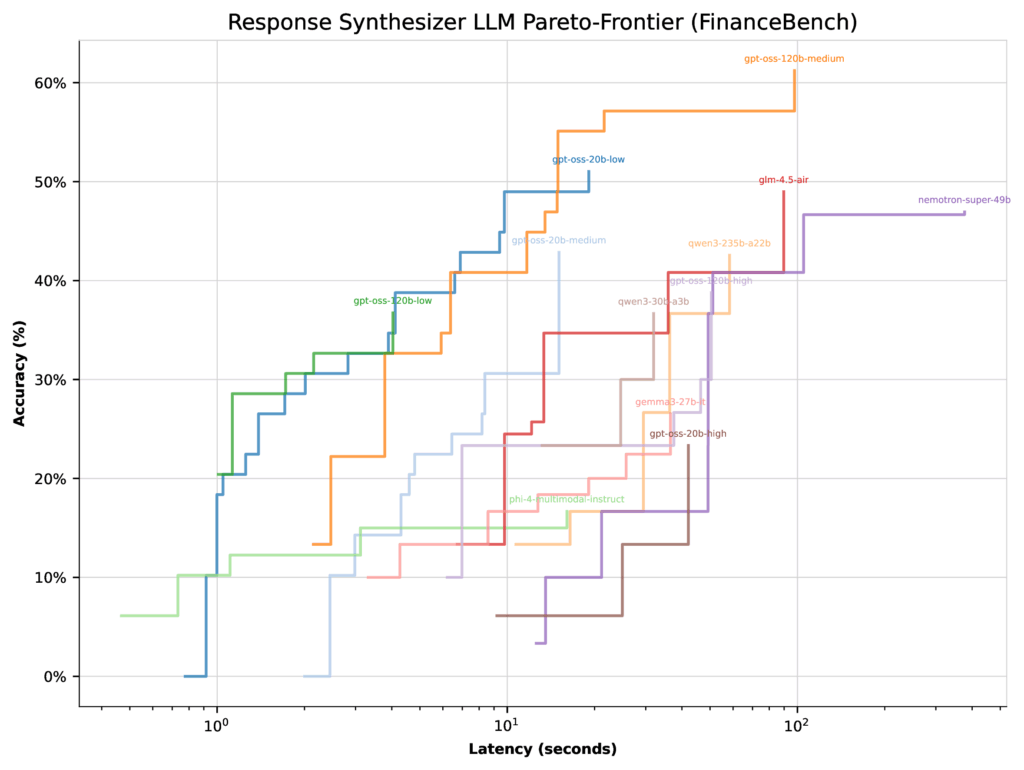
Delving Deeper: Contextualizing Performance Outcomes
At first glance, the data might seem straightforward, but a closer look reveals important subtleties. The peak accuracy of any large language model (LLM) depends not only on the model’s inherent capabilities but also on how the optimizer balances it against other models in the candidate pool.
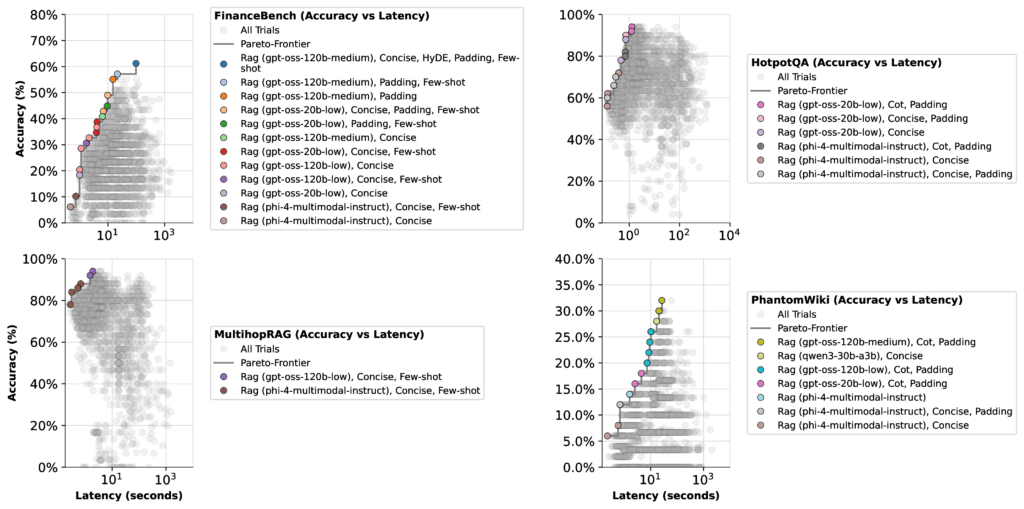
For example, on the FinanceBench dataset, when optimizing for latency, most GPT-OSS configurations (except the high thinking effort mode) clustered around similar Pareto frontiers. Here, the optimizer had limited incentive to prioritize the 20b low thinking effort model, which achieved a top accuracy of just 51%.

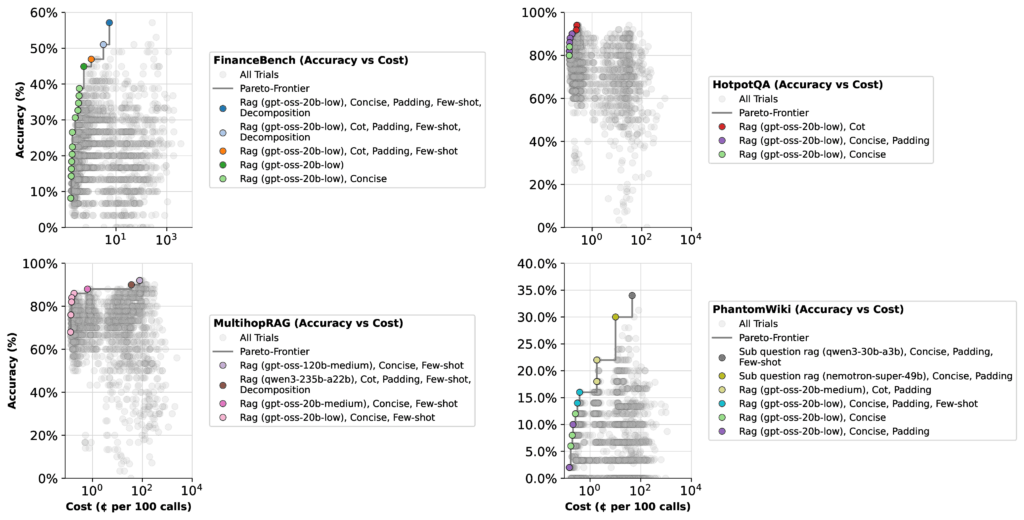
However, when shifting the focus to cost optimization, the scenario changes markedly. The 20b low thinking effort model’s accuracy jumps to 57%, while the 120b medium thinking effort model’s accuracy declines by 22%. This shift occurs because the 20b model’s lower operational cost causes the optimizer to favor it more heavily.

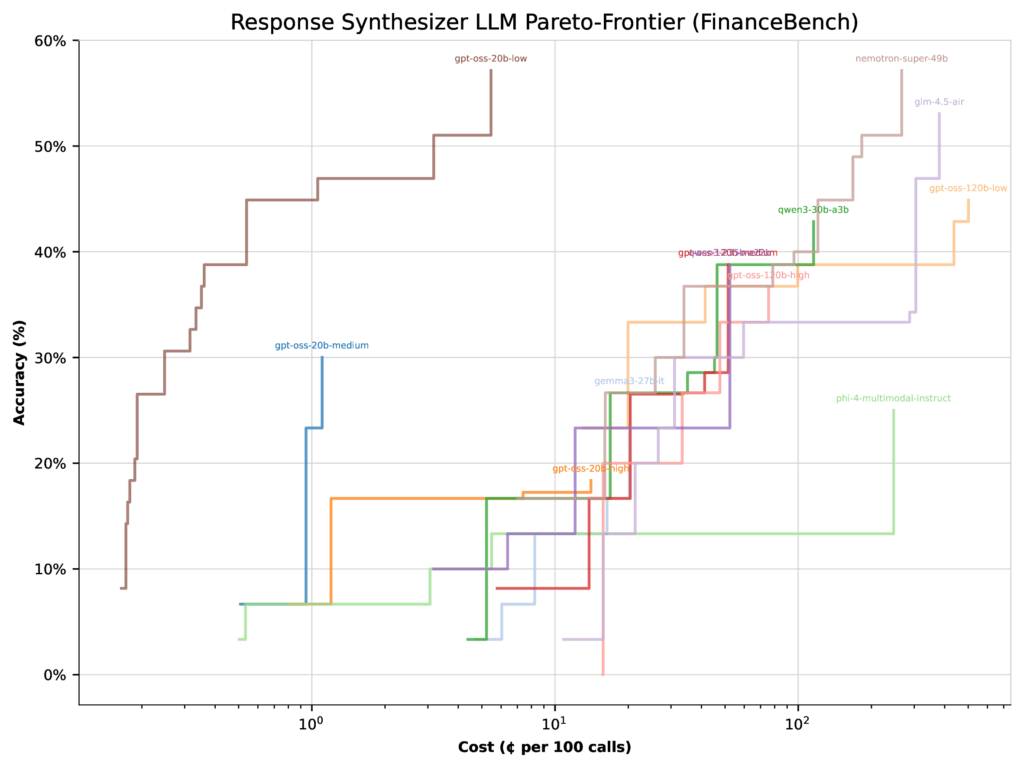
Key takeaway: Model performance is highly context-dependent. Depending on whether speed, cost, or accuracy is prioritized, optimization algorithms will select different models. Given the vast array of possible configurations, there may be even more effective setups beyond those we evaluated.
Unlocking Effective Agentic Workflows Tailored to Your Needs
The GPT-OSS models demonstrated impressive capabilities, particularly the 20b variant with low thinking effort, which often outperformed pricier alternatives. The broader lesson here is that bigger models and increased computational effort do not always translate to better accuracy. In some cases, investing more resources yields diminishing returns.
This insight motivated the creation of syftr as an open-source tool, empowering users to identify the optimal balance of cost, speed, and accuracy for their unique applications. Whether your priority is minimizing expenses, accelerating response times, or maximizing precision, syftr enables you to tailor workflows accordingly.
Explore syftr on GitHub to conduct your own experiments and discover the Pareto-efficient configurations that best suit your operational goals.





