

Alibaba has unveiled Qwen3-Max, a groundbreaking trillion-parameter Mixture-of-Experts (MoE) model, marking its most advanced foundational AI system to date. This release transitions Qwen’s roadmap for 2025 from experimental previews to full production readiness, offering immediate public access through Qwen Chat and Alibaba Cloud’s Model Studio API. The model is available in two distinct versions: Qwen3-Max-Instruct, optimized for general reasoning and coding tasks, and Qwen3-Max-Thinking, designed for enhanced “agentic” workflows that integrate external tools.
Innovations in Model Design and Scale
- Massive Scale and Architecture: Surpassing the trillion-parameter threshold, Qwen3-Max employs a sparse Mixture-of-Experts architecture that activates only select experts per token, enabling efficient scaling. Alibaba positions this as its largest and most powerful model yet, distinguishing it from incremental mid-tier upgrades.
- Training Regimen and Data Composition: The model was pretrained on an extensive dataset of approximately 36 trillion tokens, doubling the volume used for its predecessor, Qwen2.5. The training corpus emphasizes multilingual content, programming languages, and STEM-related reasoning tasks. Post-pretraining fine-tuning follows a four-phase approach: starting with long-chain-of-thought cold starts, progressing through reasoning-focused reinforcement learning, integrating thinking and non-thinking modes, and concluding with general-domain reinforcement learning.
- Availability and Access: Users can interact with Qwen3-Max via Qwen Chat’s versatile interface, while Alibaba Cloud’s Model Studio API provides advanced inference capabilities and toggles for “thinking mode.” Notably, enabling
incremental_output=trueis mandatory for activating the thinking-mode features. Model access and pricing are managed through Model Studio, with availability varying by region.
Performance Highlights: Coding, Agentic Control, and Mathematical Reasoning
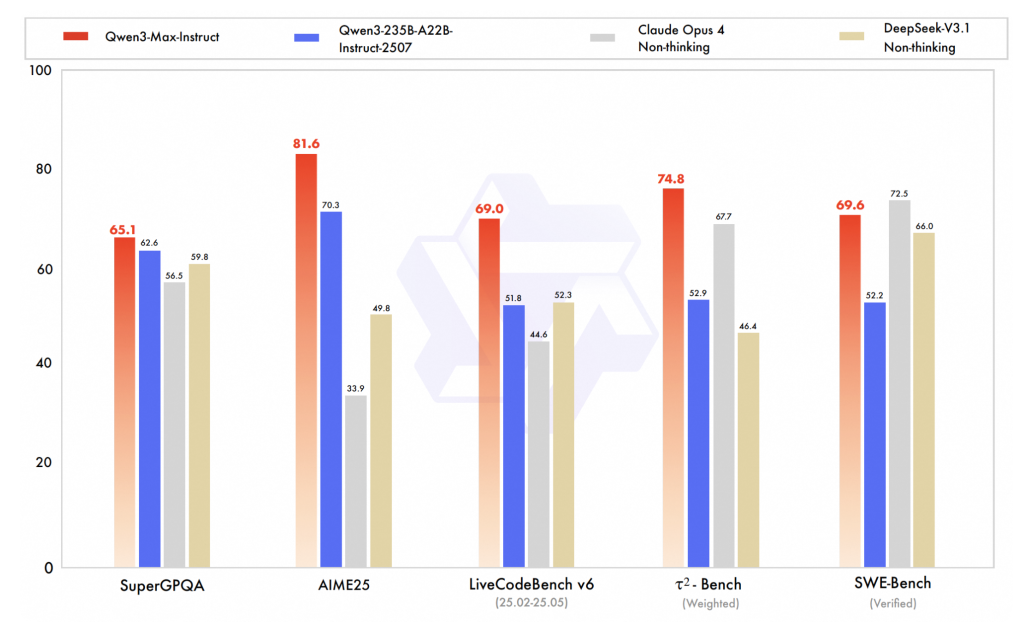
- Coding Proficiency (SWE-Bench Verified): The Qwen3-Max-Instruct variant achieves a score of 69.6 on the SWE-Bench Verified benchmark, outperforming several non-thinking baseline models such as DeepSeek V3.1, and closely trailing advanced models like Claude Opus 4. These results reflect meaningful improvements in repository-level code synthesis and reasoning under realistic evaluation conditions.
- Agentic Workflow Efficiency (Tau2-Bench): Scoring 74.8 on Tau2-Bench, which assesses multi-tool decision-making and execution, Qwen3-Max leads its peer group. This benchmark underscores the model’s enhanced capability to orchestrate complex tool interactions, a critical factor for automating sophisticated workflows.
- Advanced Mathematical Reasoning (AIME25 and Others): The Qwen3-Max-Thinking model, configured for intensive tool use and extended reasoning, reportedly achieves near-perfect accuracy on challenging math benchmarks like AIME25. While these figures await formal peer-reviewed validation, early community replications affirm the model’s strong performance in complex problem-solving scenarios.



Dual-Track Model Strategy: Instruct vs. Thinking
The Instruct variant is tailored for conventional chat, coding, and reasoning tasks, prioritizing low latency and streamlined responses. In contrast, the Thinking variant supports extended deliberation processes and explicit integration with external tools such as retrieval systems, code execution environments, web browsing, and evaluators. A critical operational detail is that Qwen3 thinking models require streaming incremental output (incremental_output=true) to function correctly, a setting that must be explicitly enabled by developers. This distinction is vital for those implementing complex toolchains or multi-step reasoning workflows.
Interpreting Performance Gains: Distinguishing Signal from Noise
- Coding Improvements: Achieving scores in the 60-70 range on SWE-Bench Verified indicates substantial capability in handling repository-scale code modifications and patch generation, beyond simple single-file tasks. These improvements are particularly relevant for development environments requiring robust code synthesis.
- Agentic Capabilities: Enhancements on Tau2-Bench reflect better multi-tool planning and decision-making, which can reduce reliance on brittle, manually crafted policies in production-grade agents, assuming the underlying tool APIs and execution environments are stable.
- Mathematical and Logical Reasoning: The near-perfect math benchmark results highlight the benefits of prolonged reasoning combined with tool assistance, such as calculators and validators. However, the transferability of these gains to open-ended, real-world tasks depends heavily on the design of evaluators and safety guardrails.
Conclusion: A Ready-to-Deploy Trillion-Parameter Powerhouse
Qwen3-Max represents a significant leap forward as a deployable trillion-parameter MoE model, complete with well-defined thinking-mode semantics and accessible through multiple platforms. While initial benchmark results are promising, ongoing internal evaluations remain essential. The model’s scale-trained on roughly 36 trillion tokens with over one trillion parameters-and the explicit API contract requiring incremental_output=true for tool-augmented operations are the most concrete takeaways. For organizations developing advanced coding assistants or agentic AI systems, Qwen3-Max offers a robust foundation for experimentation and integration with established evaluation suites like SWE-Bench and Tau2-Bench.






{kind=link}