

The StepFun AI team has unveiled Step-Audio 2 Mini, an advanced speech-to-speech large audio language model (LALM) featuring 8 billion parameters. This open-source innovation, released under the Apache 2.0 license, offers dynamic, context-aware, and real-time audio interactions. It sets a new benchmark by outperforming leading commercial models like GPT-4o-Audio in speech recognition, audio comprehension, and conversational speech tasks.

Innovative Capabilities of Step-Audio 2 Mini
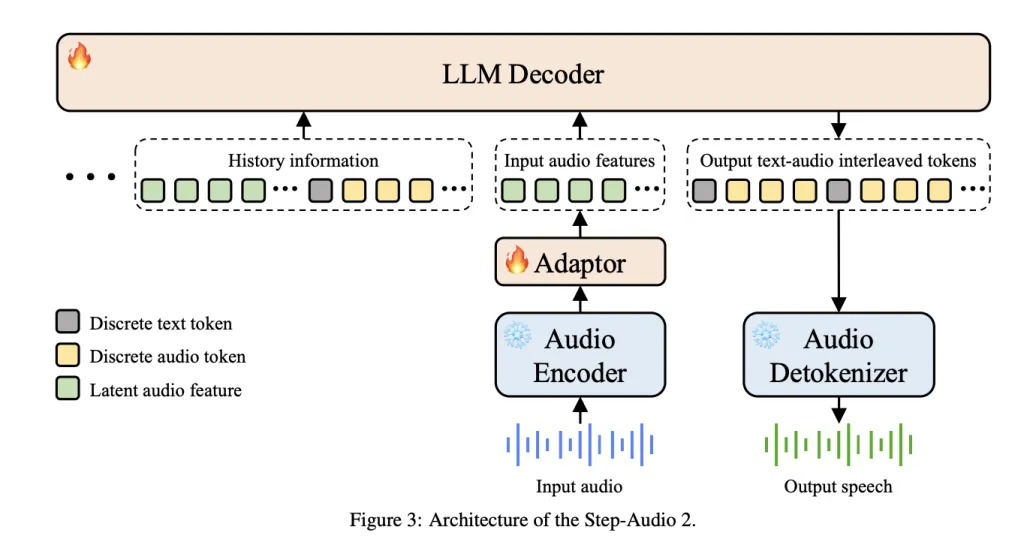
Integrated Audio-Text Tokenization for Unified Processing
Departing from traditional cascaded systems that separately handle ASR, LLM, and TTS, Step-Audio 2 Mini employs Multimodal Discrete Token Modeling. This approach merges text and audio tokens into a single, cohesive modeling stream, enabling:
- Effortless cross-modal reasoning between spoken and written language.
- Real-time switching of voice styles during audio generation.
- Consistent preservation of semantic meaning, prosody, and emotional nuance.
Emotionally Rich and Expressive Speech Synthesis
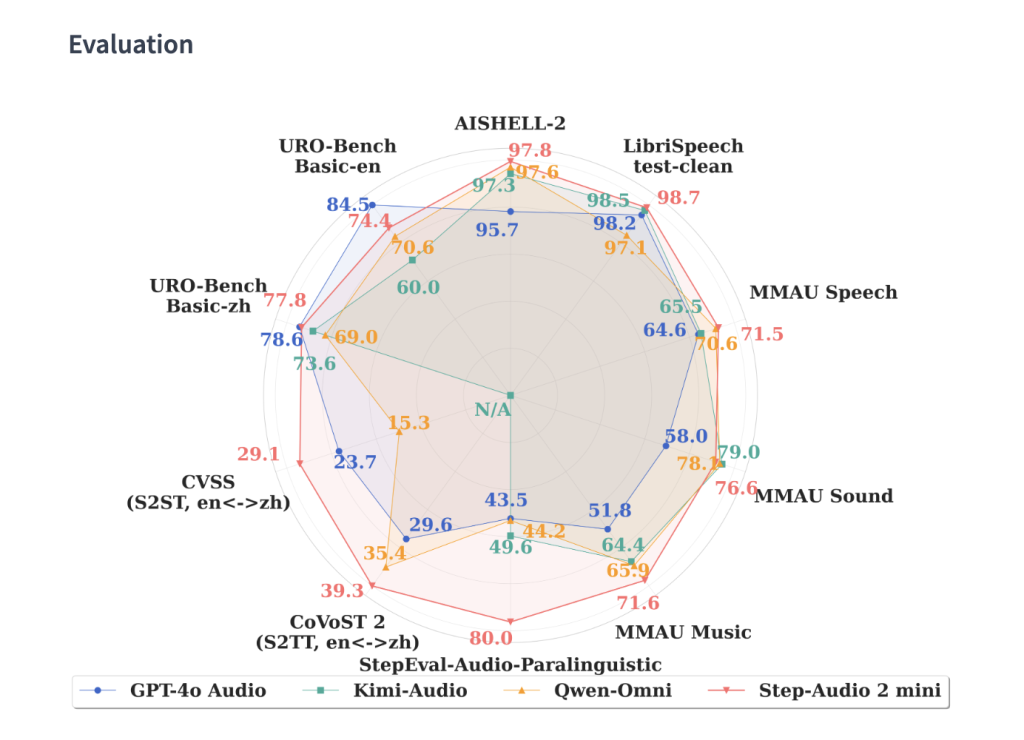
Beyond mere transcription, the model captures subtle paralinguistic cues such as intonation, tempo, emotional state, timbre, and speaking style. This allows it to generate speech that conveys authentic feelings-ranging from hushed whispers to joyful excitement. On the StepEval-Audio-Paralinguistic benchmark, Step-Audio 2 Mini achieves an impressive 83.1% accuracy, significantly surpassing GPT-4o Audio’s 43.5% and Qwen-Omni’s 44.2%.
Advanced Retrieval-Augmented Generation for Enhanced Realism
Incorporating multimodal Retrieval-Augmented Generation (RAG), the model integrates:
- Web search capabilities to ensure responses are factually grounded and up-to-date.
- Audio search functionality that accesses a vast database of real voice samples, enabling the model to mimic specific voice timbres and styles dynamically during inference.
Multimodal Reasoning and Tool Integration
Step-Audio 2 Mini extends its utility by supporting tool invocation within conversations. It matches the precision of text-based LLMs in selecting appropriate tools and parameters, while uniquely excelling in audio search tool calls-a feature absent in text-only models.
Extensive Training Dataset and Methodology
- Combined Text and Audio Tokens: 1.356 trillion tokens
- Audio Data Volume: Over 8 million hours of both real and synthetic speech
- Speaker Variety: Approximately 50,000 distinct voices spanning multiple languages and dialects
- Training Strategy: A multi-phase curriculum encompassing automatic speech recognition (ASR), text-to-speech (TTS), speech-to-speech translation, and emotion-labeled conversational synthesis
This comprehensive training enables Step-Audio 2 Mini to maintain robust textual reasoning capabilities-leveraging foundations from Qwen2-Audio and CosyVoice-while excelling in nuanced audio generation.
Benchmark Performance Highlights

Automatic Speech Recognition (ASR)
- English: Achieves a low Word Error Rate (WER) of 3.14%, outperforming GPT-4o Transcribe’s 4.5% average.
- Chinese: Records a Character Error Rate (CER) of 3.08%, significantly better than competitors GPT-4o and Qwen-Omni.
- Demonstrates resilience across diverse accents and dialects.
Audio Comprehension (MMAU Benchmark)
- Step-Audio 2 Mini: Scores 78.0 on average, surpassing Omni-R1 (77.0) and Audio Flamingo 3 (73.1).
- Excels particularly in sound and speech reasoning challenges.
Speech Translation Capabilities
- CoVoST 2 (Speech-to-Text Translation): Achieves a BLEU score of 39.26, the highest among both open-source and proprietary models.
- CVSS (Speech-to-Speech Translation): Scores 30.87 BLEU, outperforming GPT-4o’s 23.68.
Conversational AI Benchmarks (URO-Bench)
- Chinese Dialogue: Leads with scores of 83.3 (basic) and 68.2 (professional) levels.
- English Dialogue: Nearly matches GPT-4o’s 84.5 with an 83.9 score, significantly ahead of other open-source alternatives.
Summary
Step-Audio 2 Mini represents a major leap forward in accessible, multimodal speech intelligence for developers and researchers. By fusing the reasoning strengths of Qwen2-Audio with the sophisticated tokenization of CosyVoice, and enhancing it with retrieval-based grounding, StepFun AI has crafted one of the most powerful open-source audio large language models available today.





{kind=link}