

Contents Overview
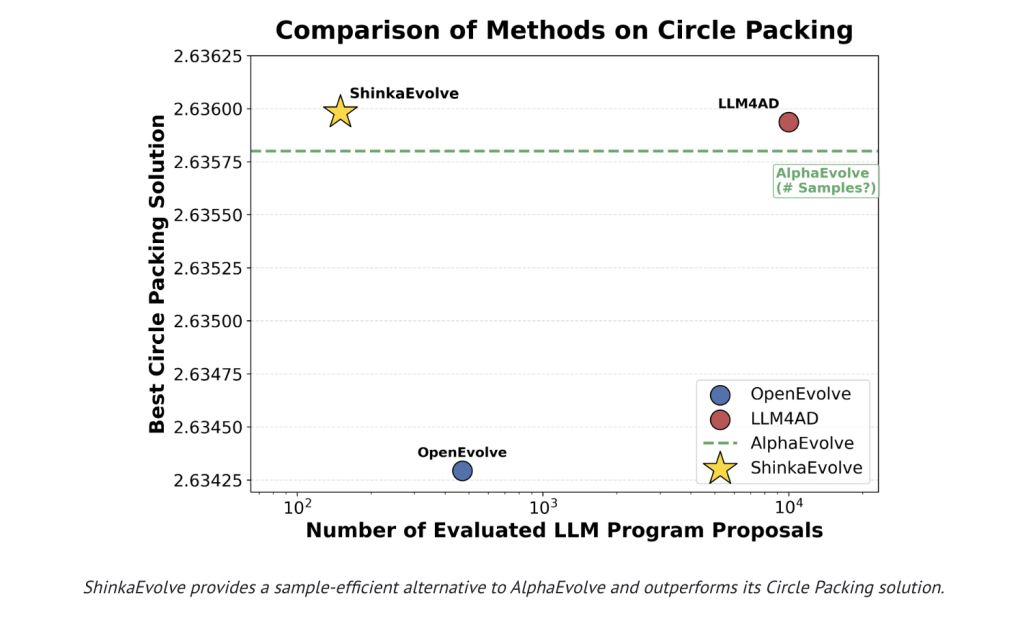
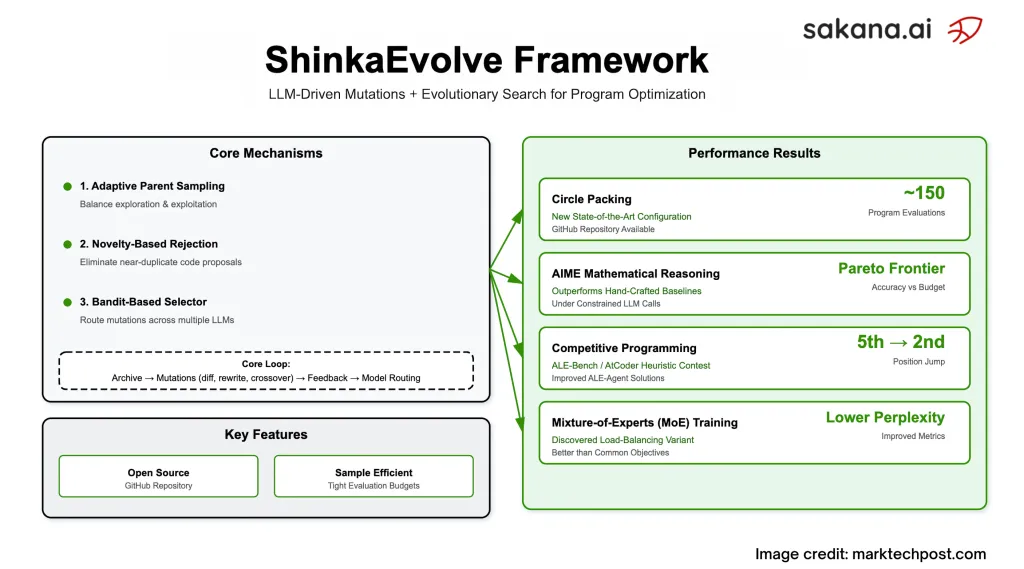
Sakana AI has introduced ShinkaEvolve, a pioneering open-source platform that leverages large language models (LLMs) as mutation engines within an evolutionary algorithm to optimize programs for complex scientific and engineering challenges. This approach significantly reduces the number of program evaluations required to discover high-quality solutions. For instance, on the classic circle-packing benchmark with 26 circles inside a unit square, ShinkaEvolve achieves a new state-of-the-art (SOTA) result using approximately 150 program evaluations, a stark contrast to previous methods that demanded thousands. The framework is available under the Apache-2.0 license, accompanied by comprehensive research documentation and accessible source code.

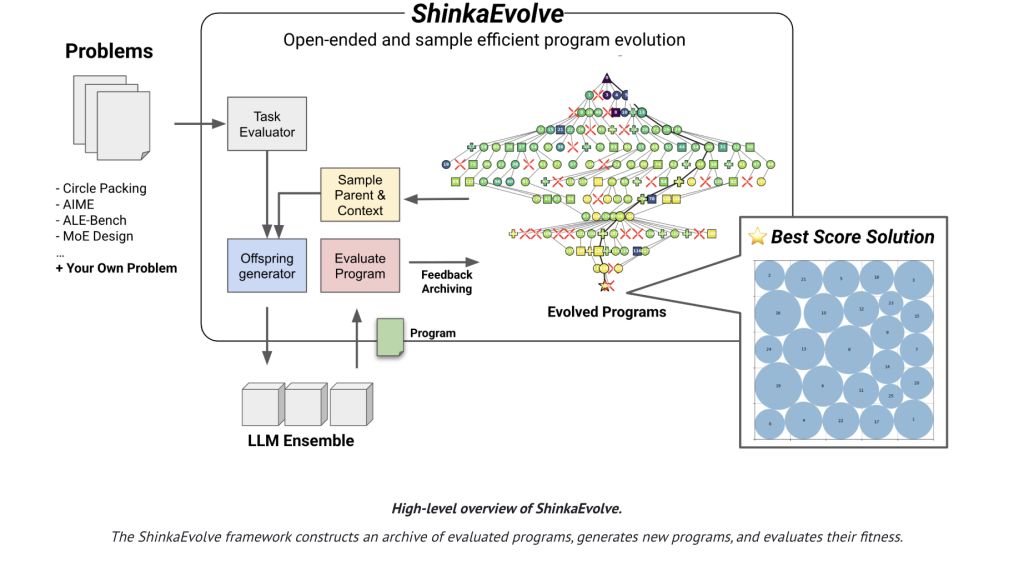
Addressing Inefficiencies in Program Evolution
Traditional agentic code evolution techniques often rely on exhaustive trial-and-error: generating mutations, executing them, scoring outcomes, and iterating-resulting in massive computational overhead. ShinkaEvolve innovates by integrating three synergistic strategies to enhance sample efficiency:
- Dynamic Parent Selection: Instead of always favoring the top-performing candidates, parents are sampled from diverse “islands” using policies that weigh both fitness and novelty. This includes power-law distributions and performance-weighted sampling, balancing exploration and exploitation effectively.
- Novelty-Driven Filtering: To prevent redundant evaluations, mutable code fragments are embedded into vector spaces. If a candidate’s similarity to existing programs exceeds a threshold, a secondary LLM acts as a “novelty evaluator” to decide whether to discard the mutation before costly execution.
- Adaptive LLM Ensemble via Bandit Algorithms: The system continuously learns which LLMs (such as GPT, Gemini, Claude, or DeepSeek variants) produce the most significant relative fitness improvements. Using a UCB1-style bandit approach, it dynamically allocates mutation tasks to the most promising models.
Demonstrated Efficiency Across Diverse Domains
ShinkaEvolve’s effectiveness extends beyond theoretical benchmarks, showing consistent performance gains across multiple challenging tasks with limited evaluation budgets:
- Circle Packing (n=26): Achieves superior configurations with roughly 150 evaluations, validated through rigorous constraint checks.
- AIME 2024 Math Reasoning: Evolves agentic scaffolds that trace a Pareto frontier balancing accuracy and LLM query costs, outperforming manually crafted baselines and generalizing across different years and LLM architectures.
- Competitive Programming (ALE-Bench LITE): Starting from ALE-Agent baselines, it delivers an average improvement of 2.3% across 10 tasks, including elevating one solution from 5th to 2nd place on an AtCoder leaderboard simulation.
- LLM Training Optimization (Mixture-of-Experts): Discovers a novel load-balancing loss function that enhances perplexity and downstream task accuracy across various regularization settings, outperforming standard global-batch load balancing.

Operational Workflow of the Evolutionary Cycle
At its core, ShinkaEvolve maintains a comprehensive archive of all evaluated programs, including their fitness scores, public metrics, and textual feedback. Each evolutionary cycle involves:
- Sampling a parent program from a selected island based on adaptive policies.
- Constructing a mutation context by combining top-performing and randomly chosen “inspiration” programs.
- Generating candidate mutations through three operators: diff-based edits, complete rewrites, and LLM-guided crossovers, while safeguarding immutable code sections with explicit markers.
- Executing candidates to update the archive and refine bandit statistics that guide future LLM selection.
- Periodically creating a meta-scratchpad summarizing recent successful strategies, which is fed back into prompts to accelerate subsequent generations.
Key Achievements and Innovations
- Circle Packing: The system autonomously discovers structured initializations (e.g., golden-angle distributions), hybrid global-local search techniques (combining simulated annealing with SLSQP), and escape strategies (like temperature reheating and ring rotations) without manual coding.
- AIME Scaffolds: Implements a three-phase expert ensemble-generation, critical peer review, and synthesis-that optimizes the trade-off between accuracy and query cost, maintaining robustness across different LLM backends.
- ALE-Bench Enhancements: Introduces targeted engineering improvements such as kd-tree subtree statistics and “targeted edge moves” to correct misclassifications, boosting performance without full rewrites.
- Mixture-of-Experts Loss: Adds an entropy-based penalty to the global-batch objective, reducing routing errors and improving perplexity and benchmark results by concentrating layer routing.
Comparison with AlphaEvolve and Other Frameworks
While AlphaEvolve showcased impressive closed-source results, it required significantly more evaluations. ShinkaEvolve not only replicates but surpasses AlphaEvolve’s circle-packing performance with dramatically fewer samples and offers full open-source transparency. The research also includes ablation studies contrasting single-model, fixed ensemble, and bandit ensemble approaches, as well as the impact of parent selection and novelty filtering, each contributing to the system’s superior efficiency.

Conclusion
ShinkaEvolve represents a breakthrough in LLM-driven program evolution, reducing evaluation requirements from thousands to mere hundreds by integrating fitness and novelty-aware parent sampling, embedding-based novelty rejection with LLM verification, and a UCB1-inspired adaptive LLM ensemble. It establishes new benchmarks in circle packing, develops more efficient AIME problem-solving scaffolds under strict query limits, enhances ALE-Bench solutions with measurable gains, and innovates a Mixture-of-Experts load-balancing loss that improves language model performance. The entire codebase and research findings are openly accessible under the Apache-2.0 license.
Frequently Asked Questions – ShinkaEvolve
1) What is ShinkaEvolve?
It is an open-source evolutionary framework that combines LLM-powered program mutations with evolutionary search techniques to automate the discovery and optimization of algorithms. Both the source code and research documentation are publicly available.
2) How does ShinkaEvolve achieve superior sample efficiency compared to previous methods?
By employing three core innovations: adaptive parent sampling that balances exploration and exploitation, novelty-based filtering to avoid redundant evaluations, and a bandit-based mechanism that dynamically selects the most effective LLMs for mutation generation.
3) What evidence supports its performance claims?
ShinkaEvolve attains state-of-the-art results on the circle-packing benchmark with only ~150 evaluations, evolves efficient scaffolds for AIME 2024 under a strict 10-query limit, and improves solutions on ALE-Bench beyond strong baselines.
4) Where can I access ShinkaEvolve, and under what license is it released?
The framework is hosted on GitHub, featuring a WebUI and example projects. It is distributed under the permissive Apache-2.0 license.





{kind=link}