

In this article, we explore a novel reinforcement learning (RL) approach grounded in a distinctive principle: divide and conquer. Diverging from conventional techniques, this method does not rely on temporal difference (TD) learning, which often faces challenges with long-horizon tasks, and instead offers a scalable alternative.


Reinforcement Learning can be effectively approached through divide and conquer, bypassing traditional temporal difference learning.
Understanding Off-Policy Reinforcement Learning
Our focus is on off-policy reinforcement learning, a framework that allows the use of diverse data sources beyond the current policy’s experience. To clarify, RL algorithms generally fall into two categories: on-policy and off-policy.
On-policy methods, such as PPO and GRPO, require fresh data generated by the current policy at every update, discarding previous experiences. This constraint limits data reuse and can be inefficient in scenarios where data collection is costly.
Conversely, off-policy RL leverages any available data, including past experiences, human demonstrations, or even internet-sourced datasets. This flexibility makes off-policy RL indispensable in domains like robotics, healthcare, and conversational AI, where gathering new data is expensive or impractical. Q-learning exemplifies a classic off-policy algorithm.
Despite advances in scaling on-policy methods, as of 2025, developing off-policy algorithms that efficiently handle complex, long-duration tasks remains an open challenge. The difficulty largely stems from how value functions are learned and updated over extended horizons.
Value Estimation Paradigms: Temporal Difference vs. Monte Carlo
Traditionally, off-policy RL employs temporal difference (TD) learning to estimate value functions, using the Bellman equation:
Q(s, a) ← r + γ maxa' Q(s', a')
Here, the value estimate for the current state-action pair depends on the immediate reward plus the discounted maximum value of the next state. However, this bootstrapping process propagates errors from future value estimates back to the current one, causing error accumulation that worsens with longer horizons.
To alleviate this, hybrid methods like n-step TD learning incorporate Monte Carlo (MC) returns for the first n steps before bootstrapping:
Q(st, at) ← ∑i=0n-1 γi rt+i + γn maxa' Q(st+n, a')
This approach reduces the number of recursive Bellman updates by a factor of n, mitigating error accumulation somewhat. At the extreme, when n approaches infinity, it becomes pure Monte Carlo learning, which uses full returns without bootstrapping.
Nevertheless, this solution is imperfect. It only lessens error propagation linearly and introduces high variance and potential suboptimality as n grows. Selecting the optimal n requires careful tuning per task, limiting general applicability.
Is there a fundamentally different strategy that can overcome these limitations?
Introducing the Divide-and-Conquer Paradigm in Value Learning
We propose a third paradigm for value estimation: divide and conquer. This method partitions a trajectory into two halves and combines their values to estimate the full trajectory’s value, reducing the number of Bellman recursions logarithmically rather than linearly.
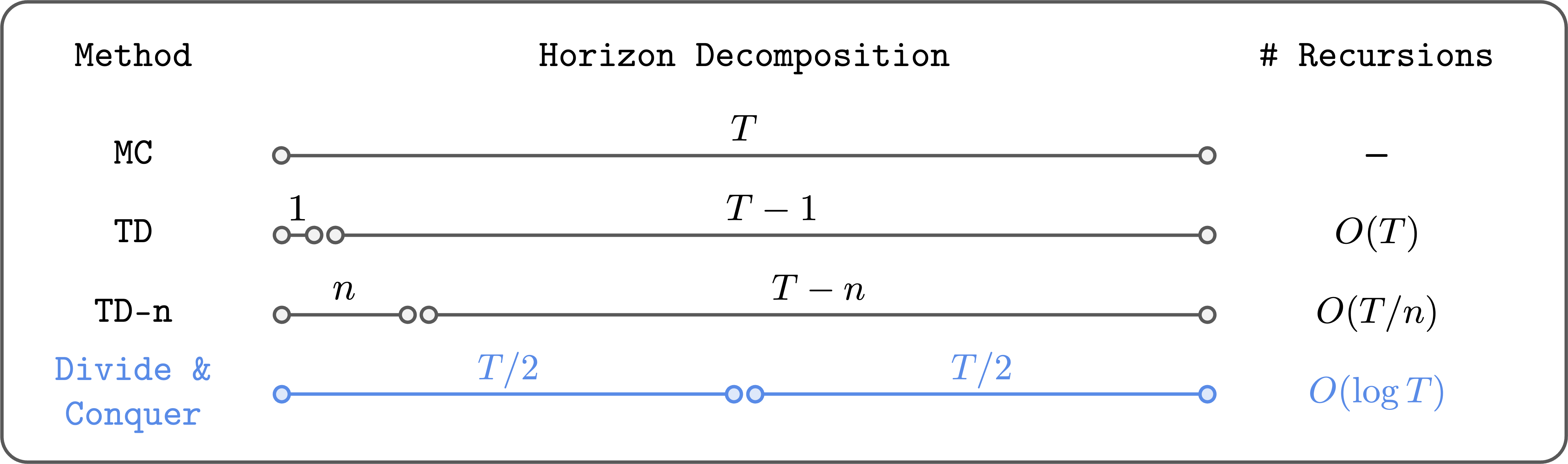

Divide and conquer dramatically decreases the recursive updates needed for value estimation.
Unlike n-step TD, this approach does not require tuning a step-size hyperparameter and avoids the high variance issues associated with long MC returns. Conceptually, it offers an elegant and scalable solution for value learning, especially in long-horizon tasks. However, practical implementation remained elusive until recently.
Realizing Divide-and-Conquer RL: The Transitive RL Algorithm
In recent collaborative research, we successfully scaled divide-and-conquer value learning to complex environments within the domain of goal-conditioned RL. This setting involves learning policies that can navigate from any initial state to any target state, naturally lending itself to divide-and-conquer strategies.
Assuming deterministic dynamics, we define the shortest path distance between states s and g as d*(s, g), which satisfies the triangle inequality:
d*(s, g) ≤ d*(s, w) + d*(w, g)
for any intermediate state w.
This translates into a transitive Bellman update for the value function V(s, g) associated with reaching goal g from state s:
V(s, g) ←
1, if s = g;
γ, if (s, g) is a direct transition;
maxw V(s, w) × V(w, g), otherwise.
Intuitively, this means the value of reaching g from s can be decomposed into values of reaching an intermediate subgoal w from s and then reaching g from w. This recursive decomposition embodies the divide-and-conquer principle.
Challenges in Practical Application
The main obstacle is identifying the optimal intermediate state w in continuous or large state spaces. While tabular methods can exhaustively search all states (akin to Floyd-Warshall shortest path computations), this is infeasible in high-dimensional environments. This limitation has historically hindered the scalability of divide-and-conquer RL.
Our Approach to Overcome the Challenge
We address this by constraining the search for w to states observed within the dataset, specifically those lying between s and g along recorded trajectories. Instead of a hard maximum, we employ a soft argmax using expectile regression, minimizing the loss:
𝔼[ℓ2κ(V(si, sj) - 𝑉̄(si, sk) × 𝑉̄(sk, sj))]
where 𝑉̄ is the target value network, ℓ2κ is the expectile loss with parameter κ, and the expectation is over tuples (si, sk, sj) sampled from trajectories with i ≤ k ≤ j.
This strategy reduces computational complexity by limiting candidate subgoals and mitigates overestimation bias inherent in max operators. We name this method Transitive RL (TRL).
Empirical Validation on Complex Long-Horizon Tasks
We evaluated TRL on challenging benchmarks from offline goal-conditioned RL, including the humanoidmaze and puzzle tasks, each involving datasets with up to one billion transitions. These tasks demand mastering intricate skills over extended horizons, sometimes exceeding 3,000 environment steps.
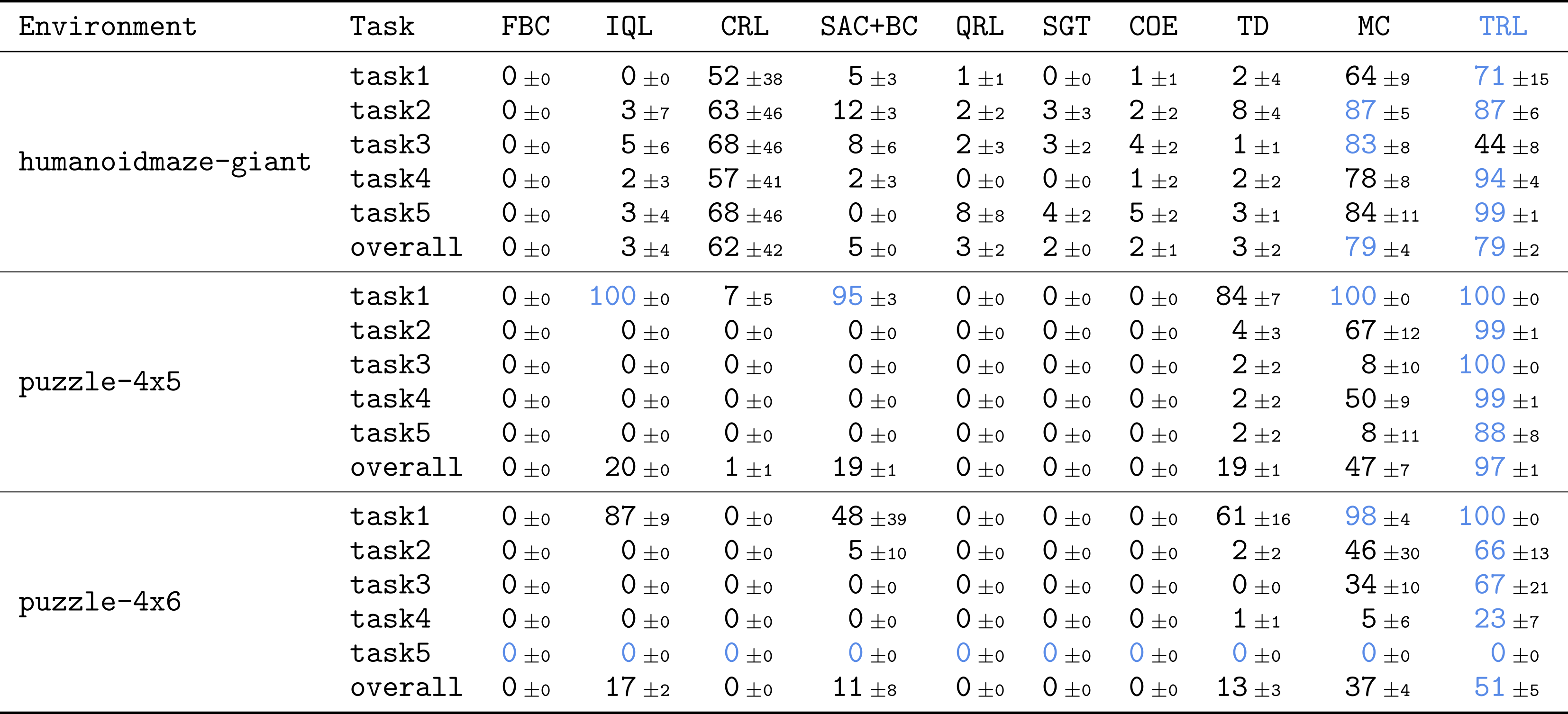

TRL outperforms strong baselines on demanding, long-horizon RL challenges.
TRL consistently achieved superior results compared to various baselines spanning TD, MC, and quasimetric learning approaches.


TRL matches the best n-step TD performance without requiring manual tuning of the step parameter n.
This comparison highlights TRL’s ability to adaptively handle trajectory decomposition without the need to predefine the length of trajectory segments, a significant advantage over n-step TD methods.
Future Directions and Open Questions
While TRL marks a significant step forward, several avenues remain for exploration:
- Extending Beyond Goal-Conditioned RL: Investigating whether the divide-and-conquer framework can be generalized to standard reward-based RL tasks. Theoretically, any reward-based problem can be reframed as goal-conditioned, suggesting promising potential.
- Handling Stochastic Environments: Current TRL assumes deterministic dynamics, but real-world settings often involve uncertainty and partial observability. Adapting TRL to stochastic domains is a critical next step.
- Algorithmic Enhancements: Opportunities exist to refine subgoal selection beyond trajectory states, reduce hyperparameter dependence, improve training stability, and simplify the overall method.
Overall, the divide-and-conquer paradigm offers a compelling path toward scalable off-policy RL, a longstanding challenge in machine learning. Alongside model-based RL and enhanced TD methods, recursive decision-making strategies like TRL could redefine how we approach complex sequential decision problems. The success of divide-and-conquer in classical algorithms such as quicksort and FFT further underscores its potential in RL.
Gratitude
Special thanks to collaborators and reviewers who contributed valuable insights to this work.






{kind=link}