

How much can we accelerate large language model inference by leveraging otherwise idle GPU compute resources, without compromising the high-quality output typical of autoregressive models? NVIDIA researchers introduce TiDAR, a novel hybrid language model architecture that combines diffusion-based token drafting with autoregressive sampling, all within a single forward pass. This approach aims to maintain the precision of autoregressive decoding while dramatically boosting throughput by utilizing free token slots available on modern GPU hardware.

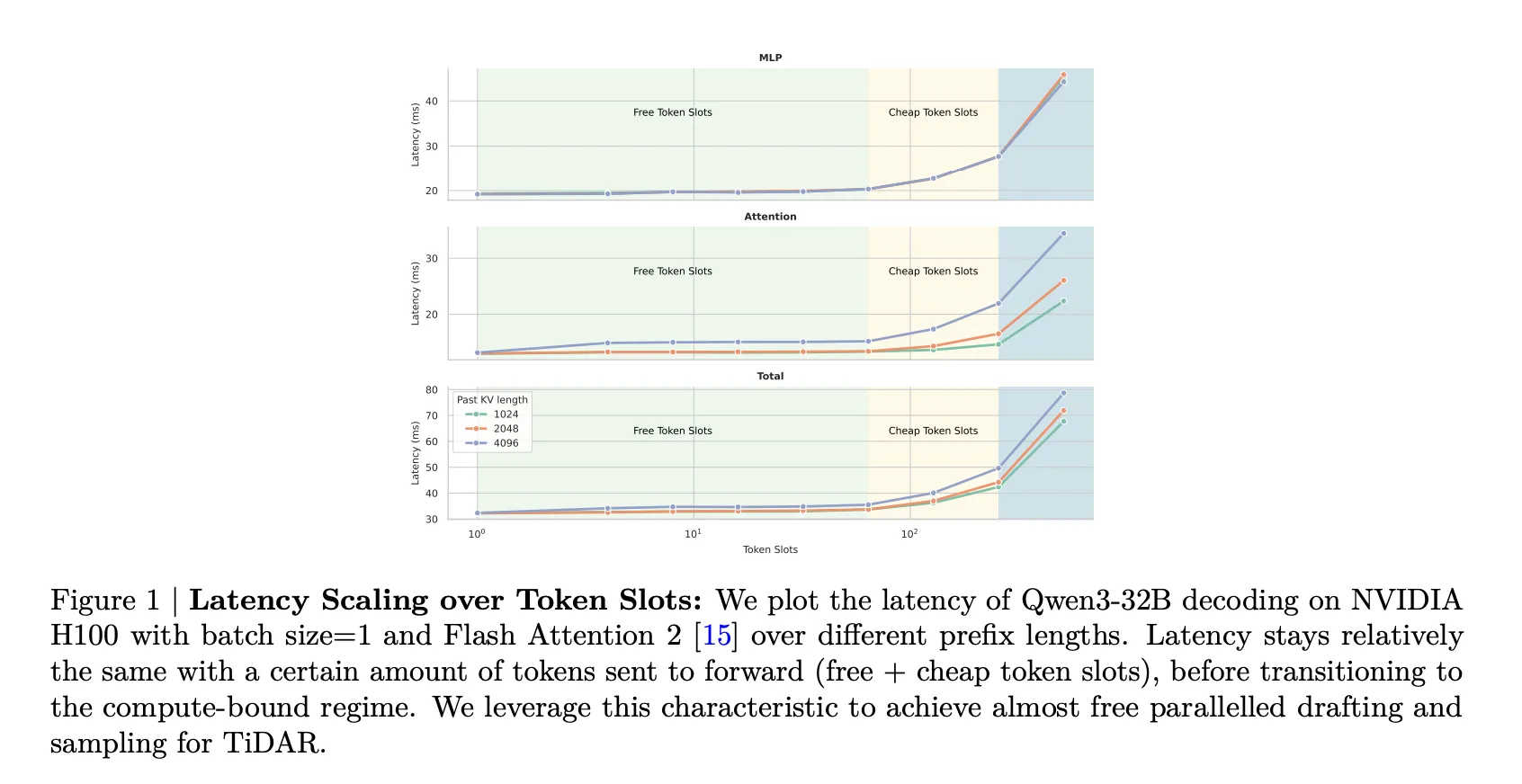
Maximizing GPU Efficiency: Free Token Slots and the Challenge of Quality
Traditional autoregressive transformers generate text by predicting one token at a time, which often leads to memory-bound latency due to frequent loading of model weights and key-value (KV) caches, rather than compute-bound floating-point operations. Increasing the input sequence length within this memory-bound regime has minimal impact on latency because the same parameters and cache are reused.
Diffusion-based masked language models have begun to exploit this by appending multiple masked tokens to a given prefix, enabling simultaneous prediction of several tokens in a single denoising step. These additional tokens are referred to as “free token slots” since profiling reveals that processing more tokens in this manner barely increases forward pass time.
Despite this advantage, diffusion LLMs such as Dream and Llada still lag behind strong autoregressive models in output quality. This is because they sample tokens independently within each step from marginal distributions conditioned on a noisy context, which undermines sequence coherence and factual accuracy. Consequently, the highest quality is often achieved by decoding only one token per step, negating much of the theoretical speed benefits of diffusion decoding.
TiDAR addresses this dilemma by preserving the computational efficiency of diffusion methods while recovering the quality of autoregressive decoding, all within a unified transformer backbone.
Innovative Architecture: Dual-Mode Backbone and Structured Attention
TiDAR’s architecture divides the token sequence at each generation step into three distinct segments:
- A prefix of tokens already accepted as final.
- A block of tokens drafted in the previous step.
- A set of mask tokens representing candidate tokens to be drafted in the upcoming step.
The model employs a carefully designed attention mask that governs interactions across these segments. Prefix tokens attend causally, supporting the autoregressive next-token prediction paradigm. Meanwhile, tokens in the drafting and mask regions attend bidirectionally within their block, enabling diffusion-style parallel marginal predictions over multiple positions. This design modifies the Block Diffusion mask by restricting bidirectional attention to the decoding block, while maintaining causal attention elsewhere.


To support both diffusion and autoregressive modes within the same model, TiDAR doubles the sequence length during training. The original input occupies the causal section, while a corrupted version fills the diffusion section. Labels in the causal part are shifted by one token to align with next-token prediction, whereas labels in the diffusion section correspond directly to input positions.
Importantly, TiDAR adopts a full mask strategy, replacing all tokens in the diffusion section with a special mask token instead of sampling sparse corruption patterns. This approach yields a dense diffusion loss, equalizes the number of loss terms between diffusion and autoregressive components, and simplifies loss balancing with a single weighting factor-typically set to 1 in experiments.


Self-Speculative Generation: Drafting and Verification in One Pass
TiDAR frames generation as a self-speculative process executed within a single forward pass per decoding step:
- Initial step: Given a prompt, the model encodes the prefix causally and performs one diffusion step over mask tokens, producing a block of drafted candidate tokens.
- Subsequent steps: Each forward pass simultaneously performs two tasks:
- Verification of drafted tokens using autoregressive logits over the extended prefix, applying a rejection sampling rule akin to speculative decoding.
- Pre-drafting the next token block via diffusion, conditioned on all possible acceptance outcomes from the current step.
Tokens accepted after verification are appended to the prefix and their KV cache entries are preserved, while rejected tokens are discarded along with their cache entries. Since drafting and verification share the same backbone and attention mask, diffusion computations efficiently utilize free token slots within the same forward pass.
TiDAR supports two sampling modes: one that favors autoregressive predictions and another that leans on diffusion outputs. Experiments with the 8B parameter model reveal that trusting diffusion predictions often enhances performance on mathematical benchmarks, while rejection sampling ensures autoregressive-level quality.
From a systems perspective, TiDAR fixes the attention layout and token count per step. It pre-initializes a block attention mask and reuses mask slices across decoding steps using Flex Attention. The architecture supports exact KV caching, avoiding recomputation of accepted tokens and introducing no additional inference-time hyperparameters.
Training Details and Model Variants
TiDAR models are developed through continual pretraining of Qwen2.5 1.5B and Qwen3 4B and 8B base models. The 1.5B variant is trained on 50 billion tokens with block sizes of 4, 8, and 16, while the 8B model is trained on 150 billion tokens using a block size of 16. Both variants utilize a maximum sequence length of 4096 tokens, cosine learning rate schedules, distributed Adam optimization, BF16 precision, and a customized Megatron-LM framework integrated with Torchtitan on NVIDIA H100 GPUs.
Evaluation benchmarks include coding tasks (HumanEval, HumanEval Plus, MBPP, MBPP Plus), mathematical reasoning (GSM8K, Minerva Math), and knowledge-based challenges (MMLU, ARC, Hellaswag, PIQA, Winogrande), all assessed via the lm_eval_harness framework.
Performance and Quality Outcomes
On generative coding and math benchmarks, the TiDAR 1.5B model competes closely with its autoregressive counterpart while generating an average of 7.45 tokens per forward pass. The 8B variant achieves a slight quality trade-off compared to Qwen3 8B but boosts generation efficiency to 8.25 tokens per forward pass.
For knowledge and reasoning tasks evaluated by likelihood, TiDAR models mirror the performance of comparable autoregressive models, benefiting from exact likelihood computation via pure causal masking. In contrast, diffusion baselines like Dream, Llada, and Block Diffusion rely on computationally intensive Monte Carlo estimators, complicating direct comparisons.
In real-world speed tests on a single NVIDIA H100 GPU with batch size 1, TiDAR 1.5B attains a 4.71× increase in decoding throughput over Qwen2.5 1.5B, measured in tokens per second. The 8B model achieves a 5.91× speedup relative to Qwen3 8B, all while maintaining comparable output quality.
Compared to diffusion LLMs, TiDAR consistently surpasses Dream and Llada in both efficiency and accuracy, especially given that diffusion models require decoding one token per forward pass for optimal quality. Against speculative decoding frameworks like EAGLE-3 and similarly trained Block Diffusion models, TiDAR leads the efficiency-quality frontier by converting more tokens per forward pass into actual output tokens per second, thanks to its unified backbone and parallel drafting-verification mechanism.
Summary of Key Insights
- TiDAR introduces a hybrid sequence-level architecture that combines diffusion-based token drafting with autoregressive sampling within a single model pass, enabled by a structured attention mask blending causal and bidirectional regions.
- It capitalizes on free token slots in GPUs by appending diffusion-drafted masked tokens to the prefix, allowing multiple positions to be processed simultaneously with minimal latency increase, thereby enhancing compute density during decoding.
- Self-speculative generation is implemented by using the same backbone to both draft candidate tokens via one-step diffusion and verify them through autoregressive logits and rejection sampling, eliminating the overhead of separate draft models typical in classic speculative decoding.
- Continual pretraining from Qwen2.5 1.5B and Qwen3 4B and 8B models with a full mask diffusion objective enables TiDAR to achieve autoregressive-level quality on coding, math, and knowledge benchmarks, while preserving exact likelihood evaluation through pure causal masking.
- In single-GPU, batch size 1 scenarios, TiDAR delivers approximately 4.71× and 5.91× more tokens per second for the 1.5B and 8B models respectively, outperforming diffusion LLMs like Dream and Llada and narrowing the quality gap with strong autoregressive baselines.
Comparative Overview
| Feature | Standard Autoregressive Transformer | Diffusion LLMs (Dream, Llada) | Speculative Decoding (EAGLE-3) | TiDAR |
|---|---|---|---|---|
| Core Concept | Predicts one token per forward pass using causal attention | Iteratively denoises masked sequences, predicting multiple tokens in parallel | Draft model proposes tokens; target model verifies and accepts a subset | Single backbone drafts via diffusion and verifies autoregressively in one pass |
| Drafting Method | None; all tokens generated by main model | Diffusion denoising over masked tokens with block or random masking | Lightweight transformer drafts tokens from current state | One-step diffusion over mask tokens appended after prefix |
| Verification Approach | Sampling from logits of causal forward pass | Typically none; relies on diffusion marginals, risking coherence loss | Target model recomputes logits and applies rejection sampling | Same backbone verifies drafts autoregressively with rejection sampling |
| Number of Models at Inference | Single model | Single model | At least two (draft and target models) | Single unified model |
| Tokens Generated per Forward Pass | 1 token | Multiple masked tokens, depending on schedule | Several draft tokens; fewer accepted | ~7.45 tokens (1.5B), ~8.25 tokens (8B) |
| Single GPU Decoding Speedup vs AR (Batch=1) | Baseline (1×) | Up to ~3×, often with quality trade-offs | ~2-2.5× speedup | 4.71× (1.5B), 5.91× (8B) |
| Quality Compared to Strong AR Baselines | Reference standard | Competitive in some cases; quality drops with fewer steps | Close when acceptance rate is high; degrades if draft model weak | Matches or closely tracks AR baselines on key benchmarks |
| Likelihood Evaluation | Exact via causal factorization | Requires Monte Carlo estimators or approximations | Exact with target model but no speed gains | Exact via pure causal masking |
| KV Cache Management | Standard cache; one token added per step | Varies; some methods rewrite segments increasing cache churn | Separate caches for draft and target models; complex bookkeeping | Unified cache; accepted tokens cached once, rejected tokens evicted |
Final Thoughts
TiDAR represents a significant advancement in unifying autoregressive and diffusion-based language modeling within a single efficient architecture. By harnessing free token slots and implementing self-speculative generation, it substantially increases tokens generated per network evaluation without sacrificing performance on challenging benchmarks like GSM8K, HumanEval, and MMLU. The full mask diffusion training objective combined with exact KV cache support makes TiDAR well-suited for production deployment on NVIDIA H100 GPUs. Overall, TiDAR demonstrates that diffusion drafting and autoregressive verification can be seamlessly integrated to deliver both speed and quality in large language model inference.





{kind=link}