Researchers from Meta Superintelligence Labs, the National University of Singapore, and Rice University have introduced REFRAG (REpresentation For RAG), an innovative decoding framework designed to enhance the efficiency of retrieval-augmented generation (RAG) in large language models (LLMs). REFRAG significantly expands the effective context window by a factor of 16 and accelerates the time-to-first-token (TTFT) by up to 30.85 times, all while maintaining high accuracy.
Challenges of Handling Extended Contexts in LLMs
Large language models rely on attention mechanisms whose computational and memory demands increase quadratically with the length of the input sequence. Doubling the input length can lead to a fourfold increase in resource consumption, which severely hampers inference speed and inflates the key-value (KV) cache size. This quadratic scaling makes deploying LLMs with long context windows impractical in many real-world applications. In RAG scenarios, although numerous retrieved passages are processed, many contribute minimally to the final output, yet the model still incurs the full computational cost of processing them.
REFRAG’s Approach to Context Compression
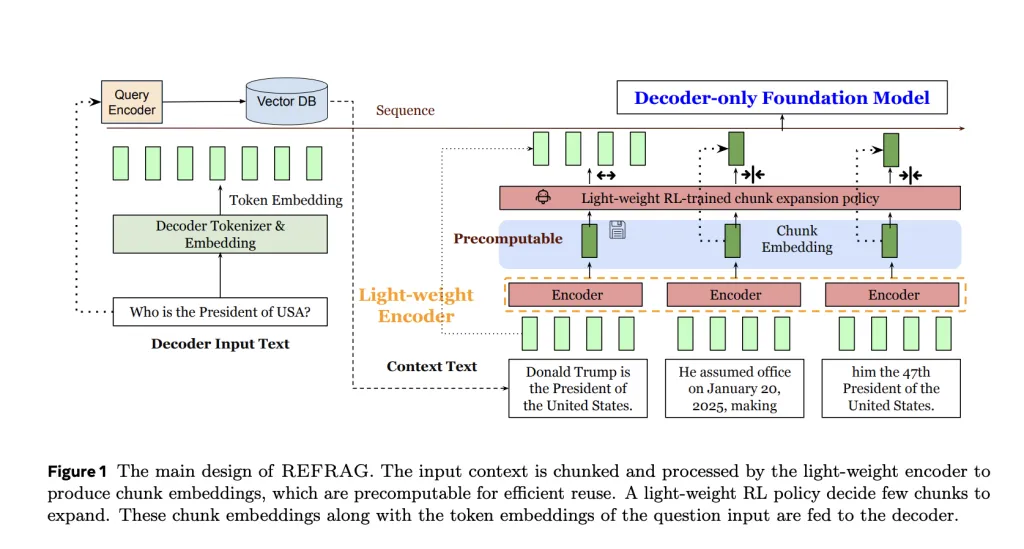
REFRAG tackles this bottleneck by introducing a lightweight encoder that segments retrieved documents into uniform chunks-typically 16 tokens each-and transforms these into dense vector embeddings called chunk embeddings. Instead of feeding thousands of raw tokens into the decoder, REFRAG supplies a condensed sequence of these embeddings, effectively reducing the input length by a factor of 16. Importantly, this method requires no modifications to the underlying LLM architecture.
REFRAG’s chunk embedding compression mechanism
Mechanisms Behind REFRAG’s Speed Gains
By drastically shortening the decoder’s input sequence, REFRAG reduces the quadratic complexity of attention computations and shrinks the KV cache size. Experimental evaluations demonstrate a remarkable 16.53× speedup in TTFT at k=16 and an even more impressive 30.85× acceleration at k=32, outperforming previous leading methods like CEPE, which only achieved 2-8× improvements. Additionally, throughput is enhanced by up to 6.78× compared to LLaMA baselines.
Maintaining Precision Through Selective Compression
To ensure that compression does not degrade output quality, REFRAG employs a reinforcement learning (RL) policy that identifies the most information-rich chunks. These critical segments bypass compression and are fed as raw tokens directly into the decoder. This selective approach preserves essential details such as precise numerical data and rare named entities. Across multiple benchmark datasets, REFRAG consistently matches or surpasses the perplexity scores of CEPE while operating with significantly reduced latency.
Empirical Validation and Performance Highlights
REFRAG was pretrained on a corpus of 20 billion tokens from the SlimPajama dataset, which includes books and arXiv papers. It was then evaluated on long-context benchmarks such as Book, Arxiv, PG19, and ProofPile. The results reveal:
A 16× extension of context length beyond the standard 4,000-token window of LLaMA-2.
Approximately 9.3% improvement in perplexity compared to CEPE across four diverse datasets.
Enhanced accuracy in scenarios with weak retrievers, where irrelevant passages are prevalent, due to REFRAG’s ability to process a larger number of passages within the same latency constraints.
REFRAG redefines the feasibility of long-context LLM applications by combining efficient passage compression with selective expansion of vital information. This approach enables processing of substantially larger inputs at unprecedented speeds without sacrificing accuracy. Consequently, REFRAG paves the way for practical deployment of large-context tasks such as comprehensive report analysis, multi-turn dialogue management, and scalable enterprise RAG systems.
Frequently Asked Questions
Q1: What exactly is REFRAG?
REFRAG (REpresentation For RAG) is a novel decoding framework developed to compress retrieved text passages into compact embeddings, enabling faster and longer-context inference in large language models.
Q2: How much faster is REFRAG compared to existing solutions?
REFRAG achieves up to 30.85× faster time-to-first-token (TTFT) and improves throughput by as much as 6.78× relative to LLaMA baselines, significantly outperforming previous methods like CEPE.
Q3: Does the compression process compromise model accuracy?
No. REFRAG uses a reinforcement learning policy to selectively bypass compression for the most critical chunks, preserving key information. This strategy ensures accuracy is maintained or even improved across various benchmarks.
Q4: Will REFRAG’s code be publicly accessible?
The developers plan to release REFRAG’s implementation on GitHub, facilitating community adoption and further research.











{kind=link}