

Is it possible for a unified AI framework to emulate a researcher’s planning, reason about complex environments, and transfer learned motions between diverse robotic platforms without starting from zero? Google DeepMind’s latest innovation, Gemini Robotics 1.5, affirms this by dividing embodied intelligence into two distinct components: one dedicated to high-level cognitive functions such as spatial reasoning, strategic planning, progress evaluation, and tool utilization, and another focused on fine-grained visuomotor execution. This architecture is designed to tackle extended, real-world challenges like multi-step packing operations or sorting waste according to localized regulations, while pioneering motion transfer to leverage data across different robotic embodiments.

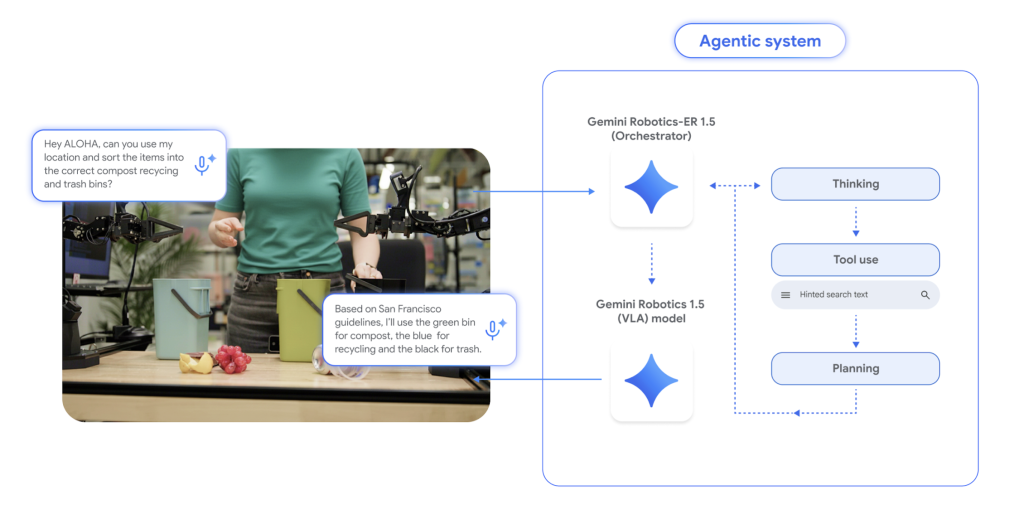
Understanding the Gemini Robotics 1.5 Framework
The system is composed of two synergistic models:
- Embodied Reasoning (ER) Module: This multimodal planner processes visual inputs such as images and videos, optionally incorporating audio cues. It grounds references through 2D spatial points, monitors task progress, and integrates external resources-like web searches or local APIs-to retrieve constraints before generating actionable sub-goals. This module is accessible through the Gemini API within Google AI Studio.
- Vision-Language-Action (VLA) Model: Serving as the executor, this model translates instructions and sensory data into precise motor commands. It uniquely produces explicit “think-before-act” reasoning traces, enabling the decomposition of complex tasks into manageable, short-term skills. Currently, access to this model is limited to select collaborators during its initial deployment phase.

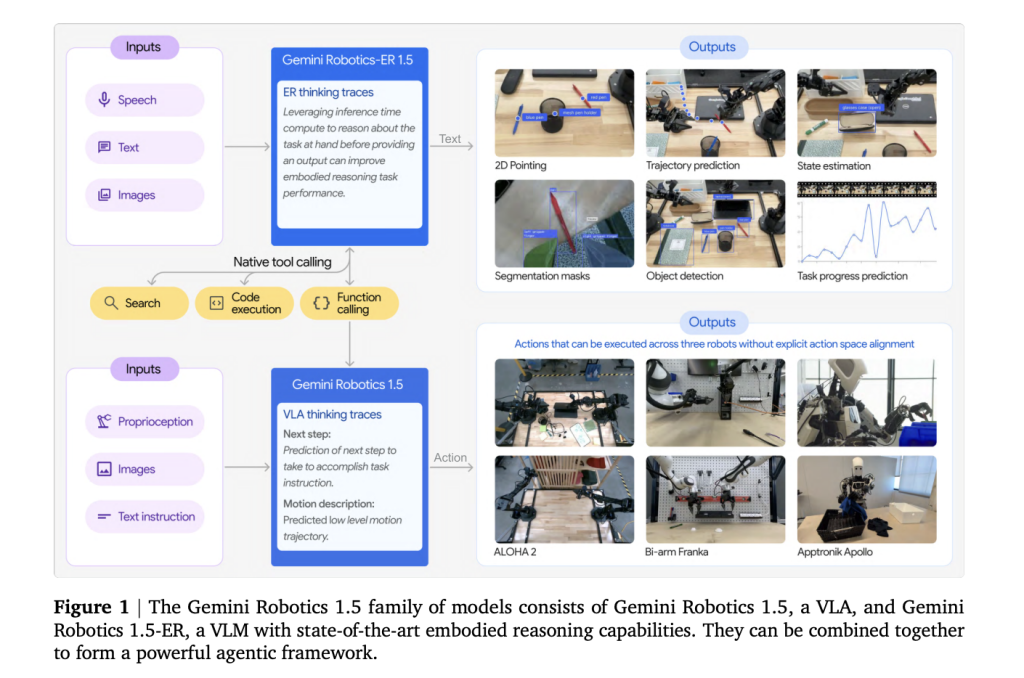
Why Separate Cognitive Reasoning from Motor Control?
Previous end-to-end Vision-Language-Action systems often struggled with robust planning, success verification, and adapting across different robotic forms. Gemini Robotics 1.5 addresses these challenges by distinctly partitioning the cognitive and control layers. The ER 1.5 module is responsible for high-level deliberation-interpreting scenes, setting sub-goals, and assessing task completion-while the VLA model specializes in executing these plans through closed-loop visuomotor control. This modular design enhances transparency by exposing internal reasoning steps, facilitates error correction, and significantly boosts reliability for long-duration tasks.
Cross-Robot Motion Transfer: A Game Changer
A standout innovation in Gemini Robotics 1.5 is Motion Transfer (MT), which enables the VLA to learn from a unified motion representation aggregated from diverse robotic platforms such as ALOHA, the dual-arm Franka, and Apptronik Apollo. This approach allows skills acquired on one robot to be directly applied to others without additional retraining, dramatically reducing the need for extensive per-robot data collection and narrowing the gap between simulation and real-world performance by leveraging shared motion priors.
Empirical Validation and Performance Metrics
The DeepMind team conducted rigorous A/B testing on physical robots and corresponding MuJoCo simulation environments, demonstrating:
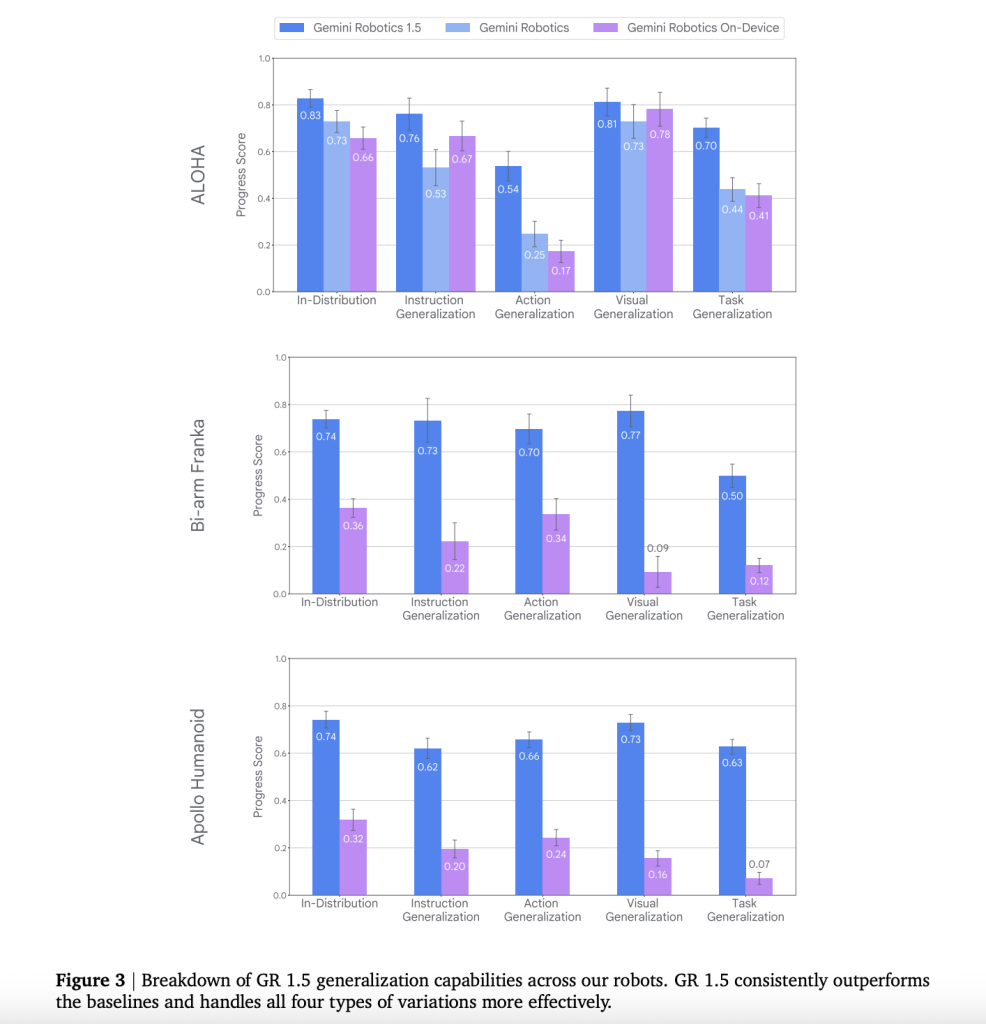
- Enhanced Generalization: Gemini Robotics 1.5 outperforms earlier Gemini baselines in following instructions, adapting actions, visual perception, and task execution across multiple robotic platforms.
- Effective Zero-Shot Skill Transfer: Motion Transfer significantly improves both task progress and success rates when transferring capabilities between robots (e.g., from Franka to ALOHA or ALOHA to Apollo), surpassing mere incremental progress improvements.
- Improved Planning Leads to Better Execution: Incorporating explicit “thinking” traces within the VLA enhances completion rates for long-horizon tasks and stabilizes plan adjustments during task execution.
- Superior End-to-End Agent Performance: Combining the ER 1.5 planner with the VLA executor yields substantial gains in complex multi-step activities such as desk organization and cooking-like sequences, outperforming previous Gemini-2.5-Flash orchestrators.

Robust Safety Measures and Comprehensive Evaluation
DeepMind emphasizes a multi-layered safety framework encompassing policy-aligned dialogue and planning, safety-conscious grounding to avoid hazardous interactions, adherence to physical constraints, and extensive evaluation protocols. These include advanced ASIMOV-style scenario testing and automated adversarial red-teaming designed to uncover edge-case failures, such as hallucinated affordances or non-existent objects, before any physical actuation occurs.
Positioning Within the Robotics Industry
Gemini Robotics 1.5 marks a significant evolution from traditional “single-instruction” robotic systems toward truly agentic platforms capable of multi-step autonomous operations, explicit integration of web and tool usage, and cross-platform learning. This capability suite is highly relevant for both consumer-grade and industrial robotics applications. Initial access is prioritized for established robotics manufacturers and humanoid robot developers.
Essential Insights and Highlights
- Dual-Model Design (ER ↔ VLA): The ER 1.5 module manages embodied reasoning tasks such as spatial grounding, planning, success and progress estimation, and tool invocation, while the VLA model executes motor commands based on vision-language inputs.
- “Think-Before-Act” Paradigm: The VLA generates explicit intermediate reasoning steps during task execution, facilitating better task segmentation and dynamic plan adjustments.
- Cross-Embodiment Motion Transfer: A single VLA checkpoint enables skill reuse across heterogeneous robots (ALOHA, Franka, Apollo), supporting zero- or few-shot transfer without retraining per platform.
- Tool-Enhanced Planning: ER 1.5 can query external resources like web searches to incorporate contextual constraints-such as local weather or city-specific recycling regulations-into its planning process.
- Documented Performance Gains: The system demonstrates superior instruction following, action generalization, visual adaptability, and task success on both real hardware and aligned simulators, including cross-robot skill transfers and long-horizon task execution.
- Access and Availability: The ER 1.5 module is publicly accessible via the Gemini API on Google AI Studio, complete with documentation and examples, while the VLA model remains available to select partners with a public waitlist.
- Safety and Evaluation Commitment: DeepMind integrates layered safeguards, including policy-aligned planning, safety-aware grounding, physical constraints, and enhanced ASIMOV benchmarks alongside adversarial testing to mitigate risks and hallucinations.
In Conclusion
Gemini Robotics 1.5 pioneers a clear division between high-level embodied reasoning and low-level control, introduces motion transfer to efficiently share data across robotic platforms, and exposes its reasoning capabilities-such as spatial grounding, progress tracking, and tool integration-through the Gemini API. This architecture not only reduces the data demands for each robot but also enhances reliability for complex, long-duration tasks, all while maintaining a strong focus on safety through rigorous testing and protective measures.





{kind=link}