

Large language models (LLMs) frequently produce what are known as “hallucinations”-outputs that sound confident and convincing but are factually incorrect. Despite advances in model architectures and training techniques, these hallucinations remain a persistent challenge. Recent research from OpenAI offers a comprehensive explanation: hallucinations arise from fundamental statistical characteristics inherent in supervised versus self-supervised learning, compounded by evaluation methods that inadvertently encourage such errors.
Understanding the Statistical Roots of Hallucinations
The study frames hallucinations as intrinsic errors tied to the nature of generative modeling. Even when training data is flawless, the cross-entropy loss function used during pretraining imposes statistical constraints that inevitably lead to mistakes.
To analyze this, researchers simplified the problem into a supervised binary classification task dubbed Is-It-Valid (IIV), which assesses whether a model’s output is correct or erroneous. Their findings reveal that the hallucination rate in an LLM is at least double the misclassification rate observed in the IIV task. Essentially, hallucinations occur for reasons similar to those behind misclassifications in supervised learning: uncertainty about knowledge (epistemic uncertainty), model limitations, shifts in data distribution, or noisy inputs.
Why Do Rare or Unique Facts Lead to More Hallucinations?
A key factor driving hallucinations is the singleton rate-the proportion of facts that appear only once in the training dataset. Drawing parallels to Good-Turing frequency estimation, if 20% of facts are singletons, then at least 20% of those facts are likely to be hallucinated. This explains why LLMs reliably recall common knowledge, such as the capital of France, but often falter when asked about obscure or seldom-mentioned information.
Model Limitations as a Source of Hallucinations
Hallucinations can also stem from the inherent constraints of the model architecture. When a model’s representational capacity is insufficient to capture certain patterns, systematic errors emerge. For instance, early n-gram language models frequently generated grammatically incorrect sentences, while some modern token-based models struggle with tasks like accurately counting characters because individual letters are embedded within subword tokens. These architectural shortcomings cause persistent errors even when the training data is adequate.

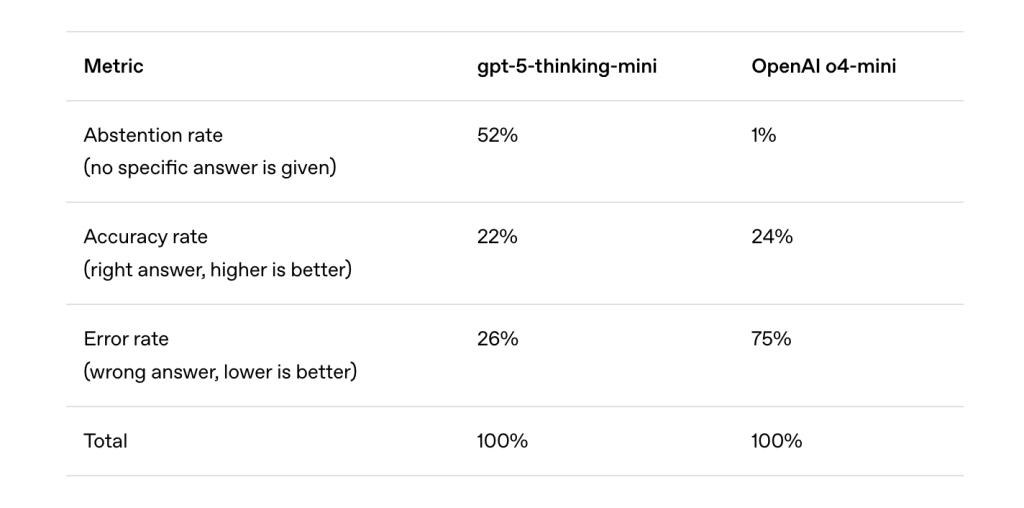
Why Post-Training Techniques Don’t Fully Eradicate Hallucinations
Methods applied after initial training-such as Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), and Reinforcement Learning with AI Feedback (RLAIF)-can reduce certain types of errors, particularly harmful or misleading outputs. However, overconfident hallucinations persist because the evaluation frameworks guiding these improvements are misaligned with the goal of minimizing false confident assertions.
Much like students guessing answers on multiple-choice tests, LLMs are incentivized to “guess” when uncertain. Popular benchmarks like MMLU, GPQA, and SWE-bench typically use binary scoring systems: correct answers receive full credit, abstentions (“I don’t know”) earn none, and incorrect answers are penalized no more than abstentions. This scoring encourages models to guess rather than admit uncertainty, thereby perpetuating hallucinations.
How Evaluation Leaderboards Encourage Overconfident Errors
An examination of widely used benchmarks reveals that nearly all employ binary grading without rewarding expressions of uncertainty. Consequently, models that honestly indicate when they lack confidence tend to score lower than those that always provide an answer, regardless of accuracy. This dynamic pressures developers to prioritize confident responses over well-calibrated ones, reinforcing the cycle of hallucinations.
Proposed Solutions to Mitigate Hallucinations
The researchers advocate for a socio-technical approach to address hallucinations, emphasizing that changes in evaluation protocols are as crucial as improvements in model design. They suggest implementing explicit confidence thresholds in benchmarks, where models are penalized for incorrect answers and receive partial credit for abstaining when uncertain.
For example, a scoring scheme might be: “Respond only if confidence exceeds 75%. Correct answers earn 1 point; incorrect answers lose 2 points; ‘I don’t know’ responses earn 0 points.”
This approach mirrors traditional exam formats like earlier versions of the SAT and GRE, where guessing was discouraged through penalties. Such a system promotes behavioral calibration, encouraging models to withhold answers when unsure, thereby reducing overconfident hallucinations while still optimizing for performance.
Broader Impact and Future Directions
This research reframes hallucinations not as mysterious anomalies but as predictable consequences of current training objectives and evaluation misalignments. Key takeaways include:
- Inherent pretraining limitations: Hallucinations are analogous to classification errors in supervised learning.
- Post-training effects: Binary evaluation metrics incentivize risky guessing behavior.
- Need for evaluation reform: Incorporating uncertainty-aware scoring can realign incentives and enhance model reliability.
By linking hallucinations to established principles in learning theory, this work demystifies their origins and points toward practical strategies that shift the focus from solely refining model architectures to redesigning evaluation frameworks.






{kind=link}