

How can artificial intelligence systems intelligently select the most suitable model or tool for each phase of a complex task, rather than defaulting to a single large model for all operations? NVIDIA researchers have introduced ToolOrchestra, an innovative approach that trains a compact language model to serve as the central coordinator-the ‘conductor’-of a multi-tool AI agent.

Transitioning from Monolithic AI Models to Intelligent Orchestration
Traditionally, AI agents rely on a single, large-scale model-such as GPT-5-to interpret prompts, decide when to invoke external tools like web search or code interpreters, and perform all reasoning internally. This monolithic approach often leads to inefficiencies and overuse of heavyweight models.
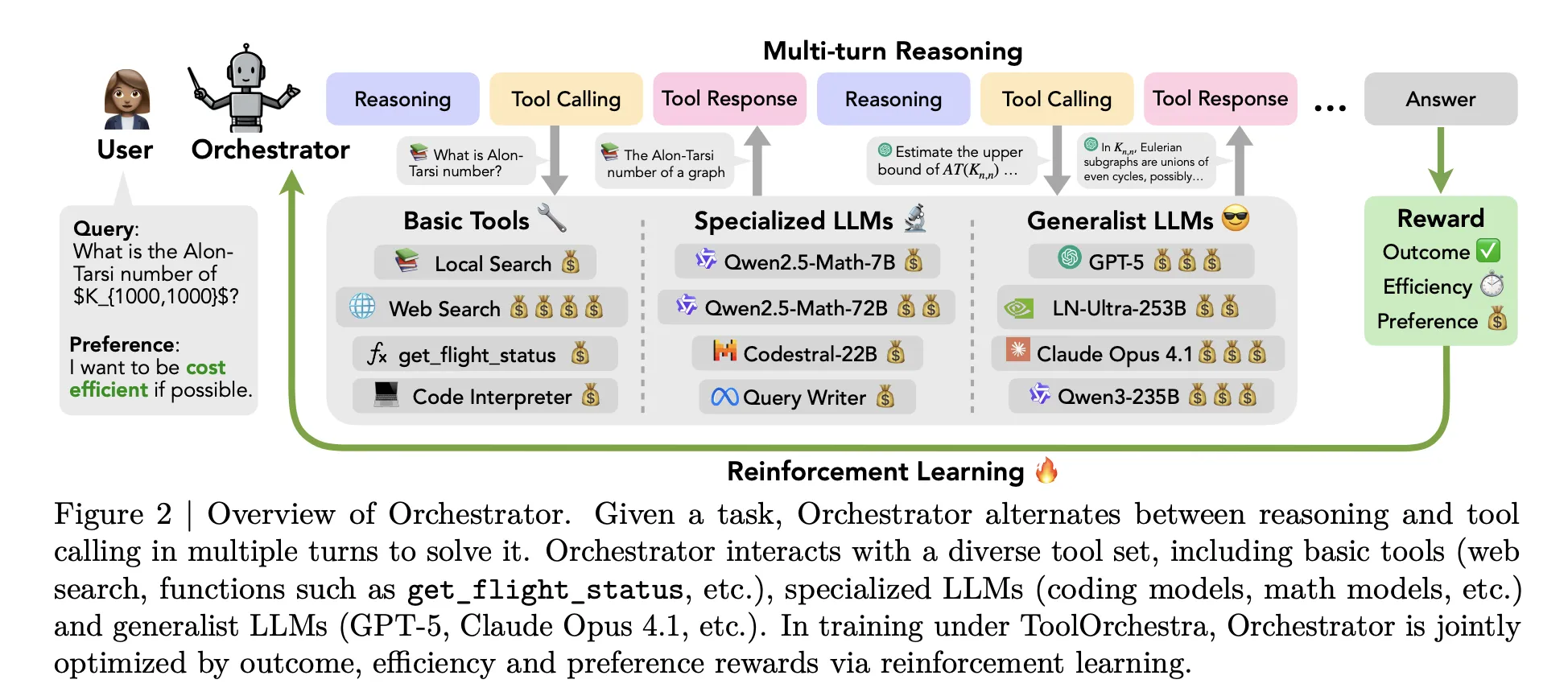
ToolOrchestra revolutionizes this paradigm by introducing a specialized controller model named Orchestrator-8B. This orchestrator treats both conventional tools and various large language models (LLMs) as modular, callable components, enabling dynamic and context-aware tool selection.
Initial experiments highlight the limitations of naive prompting strategies. For instance, when the Qwen3-8B model is prompted to route tasks among GPT-5, GPT-5 mini, Qwen3-32B, and Qwen2.5-Coder-32B, it disproportionately delegates 73% of tasks to GPT-5. Similarly, GPT-5 self-orchestrating favors itself or its mini variant in 98% of cases. These tendencies, termed self-enhancement and other-enhancement biases, result in excessive reliance on powerful models, disregarding cost and efficiency considerations.
To overcome these biases, ToolOrchestra employs reinforcement learning to train a compact orchestrator explicitly optimized for multi-step routing decisions.
Introducing Orchestrator-8B: The Compact Conductor
Orchestrator-8B is an 8-billion parameter decoder-only Transformer, fine-tuned from the Qwen3-8B base model and publicly available on Hugging Face. During inference, it operates in a multi-turn loop alternating between reasoning and tool invocation, structured into three key phases:
- Input Processing: The orchestrator ingests the user’s instruction along with optional natural language preferences, such as prioritizing low latency or avoiding web searches.
- Reasoning and Planning: It internally generates a chain-of-thought style reasoning sequence to formulate the next action.
- Tool Selection and Execution: It selects an appropriate tool from a predefined set and issues a structured JSON-formatted tool call. The environment executes this call, returns the output as an observation, and feeds it back for subsequent steps. This iterative process continues until a termination signal is produced or a maximum of 50 turns is reached.
The toolset is categorized into three groups: basic utilities (e.g., Tavily web search, a Python sandbox interpreter, and a local Faiss index powered by Qwen3-Embedding-8B), specialized LLMs (such as Qwen2.5-Math-72B and Qwen2.5-Coder-32B), and generalist LLMs (including GPT-5, GPT-5 mini, Llama 3.3-70B-Instruct, and Qwen3-32B). All tools adhere to a unified schema detailing names, natural language descriptions, and typed parameter specifications.
End-to-End Reinforcement Learning with Multi-Faceted Rewards
ToolOrchestra frames the orchestration challenge as a Markov Decision Process (MDP), where the state encapsulates the conversation history, prior tool calls, observations, and user preferences. Actions correspond to the next textual output, encompassing both reasoning tokens and tool call schemas. After up to 50 steps, a scalar reward evaluates the entire trajectory.
The reward function integrates three components:
- Outcome Reward: A binary signal indicating task success. For open-ended tasks, GPT-5 serves as an evaluator, comparing outputs against reference answers.
- Efficiency Reward: Penalizes monetary cost and latency, with token usage mapped to real-world pricing based on public APIs and Together AI’s rates.
- Preference Reward: Measures alignment with user-specified preferences, which can emphasize cost, latency, or tool-specific usage.
These components are combined into a single scalar reward via a preference vector, guiding the training process.
The policy is optimized using Group Relative Policy Optimization (GRPO), a policy gradient method that normalizes rewards within groups of trajectories for the same task, enhancing training stability. Additionally, trajectories with invalid tool calls or low reward variance are filtered out to further stabilize learning.

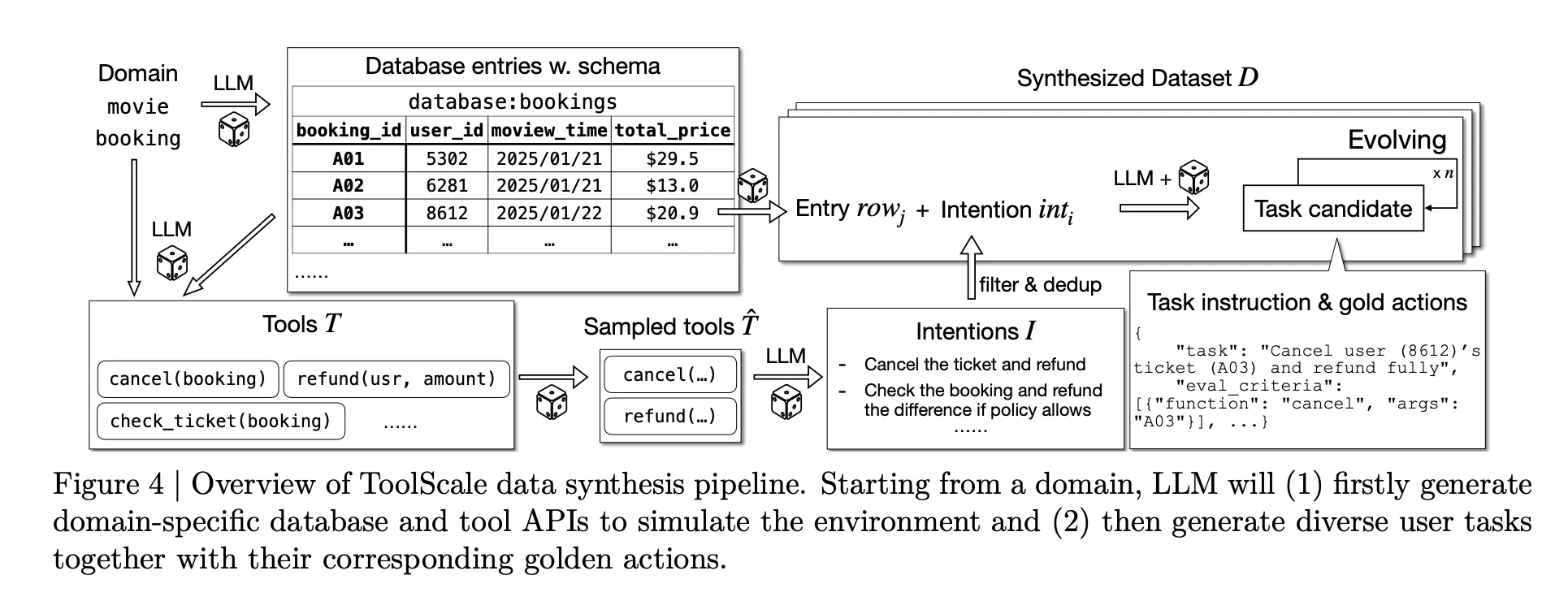
To scale training, the team plans to launch ToolScale, a synthetic dataset featuring multi-step tool invocation tasks. For each domain, an LLM generates database schemas, entries, domain-specific APIs, and diverse user tasks with ground truth sequences of function calls and intermediate data requirements.
Performance Benchmarks and Cost Efficiency
Orchestrator-8B was evaluated on three rigorous benchmarks: Humanity’s Last Exam, FRAMES, and τ² Bench, each designed to test long-horizon reasoning, factual accuracy under retrieval, and function calling in dual control environments.
On Humanity’s Last Exam’s text-only questions, Orchestrator-8B achieved 37.1% accuracy, outperforming GPT-5’s 35.1%. On FRAMES, it scored 76.3% versus GPT-5’s 74.0%, and on τ² Bench, it reached 80.2% compared to GPT-5’s 77.7%.


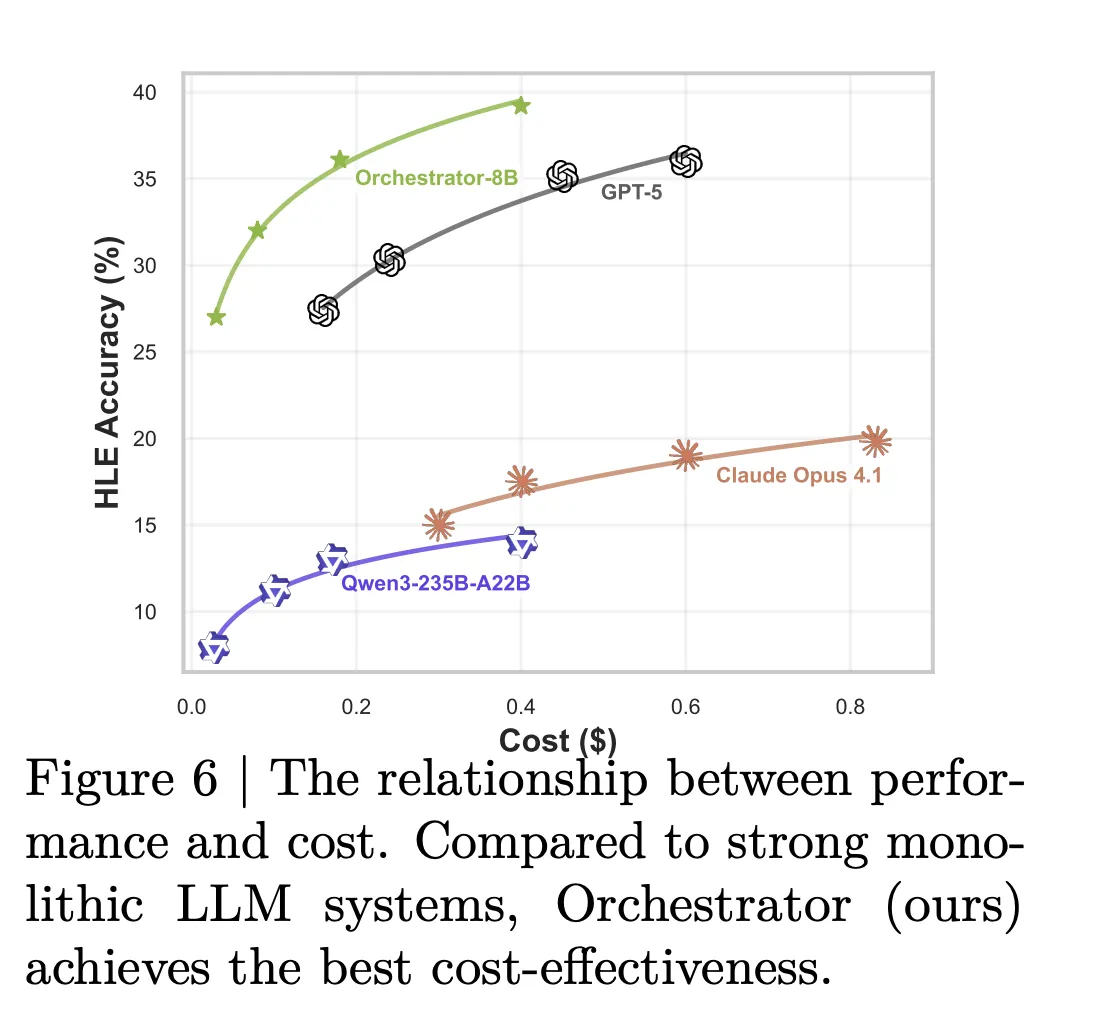
Efficiency gains are even more pronounced. When utilizing a combination of basic, specialized, and generalist LLM tools, Orchestrator-8B averages a cost of 9.2 cents and latency of 8.2 minutes per query across Humanity’s Last Exam and FRAMES benchmarks. In contrast, GPT-5 incurs 30.2 cents and 19.8 minutes on average. This translates to Orchestrator-8B operating at roughly 30% of GPT-5’s monetary cost and completing tasks approximately 2.5 times faster.
Analysis of tool usage reveals that other orchestrators, such as Claude Opus 4.1, predominantly call GPT-5, while GPT-5 as its own orchestrator favors GPT-5 mini. Orchestrator-8B, however, distributes calls more evenly across powerful, cost-effective models, search engines, local retrieval, and code interpreters, achieving superior accuracy at reduced cost within the same turn budget.

Further generalization tests replaced training-time tools with unseen models such as OpenMath Llama-2-70B, DeepSeek-Math-7B-Instruct, Codestral-22B-v0.1, Claude Sonnet-4.1, and Gemma-3-27B. Even in this setting, Orchestrator-8B maintained the best balance of accuracy, cost, and latency among all baselines. Additionally, a preference-aware evaluation demonstrated that Orchestrator-8B more closely adheres to user tool usage preferences than GPT-5, Claude Opus-4.1, and Qwen3-235B-A22B under identical reward metrics.
Summary of Insights
- ToolOrchestra introduces Orchestrator-8B, an 8-billion parameter model trained via reinforcement learning to intelligently select and sequence tools and LLMs for multi-step tasks, optimizing for outcome, efficiency, and user preferences.
- Orchestrator-8B is openly available on Hugging Face and designed to seamlessly coordinate diverse tools-including web search, code execution, retrieval, and specialized LLMs-through a standardized interface.
- It surpasses GPT-5 in accuracy on benchmarks like Humanity’s Last Exam (37.1% vs. 35.1%) while being approximately 2.5 times more efficient, and outperforms GPT-5 on τ² Bench and FRAMES at roughly 30% of the cost.
- The research highlights that naive prompting of a single large model as its own router leads to self-enhancement bias, causing overuse of certain models. In contrast, a dedicated orchestrator learns a balanced, cost-aware routing strategy across multiple tools.
Concluding Remarks
NVIDIA’s ToolOrchestra marks a significant advancement toward modular AI systems where a compact orchestration model governs the selection and sequencing of tools and LLMs, rather than relying on a single monolithic model. Demonstrating substantial improvements in accuracy, latency, and cost-efficiency across multiple challenging benchmarks, this approach paves the way for more scalable, budget-conscious AI deployments. By elevating orchestration policy to a primary optimization target, ToolOrchestra sets a new standard for intelligent multi-tool AI agents.





{kind=link}