

How can we develop AI systems capable of autonomous planning, reasoning, and decision-making over extended sequences without continuous human intervention? Moonshot AI introduces Kimi K2 Thinking, an advanced open-source cognitive agent model that reveals the entire reasoning process within the Kimi K2 Mixture of Experts (MoE) framework. This model is tailored for complex tasks requiring profound reasoning, prolonged tool utilization, and consistent agent performance across hundreds of sequential steps.

Introducing Kimi K2 Thinking: A New Era in AI Reasoning Agents
Kimi K2 Thinking represents the cutting edge of Moonshot AI’s open-source reasoning models. Designed as a cognitive agent, it performs stepwise reasoning while dynamically invoking external tools during inference. This interleaving of thought chains and function calls enables the model to read, analyze, execute tool calls, and iterate this process seamlessly for hundreds of steps without human input.
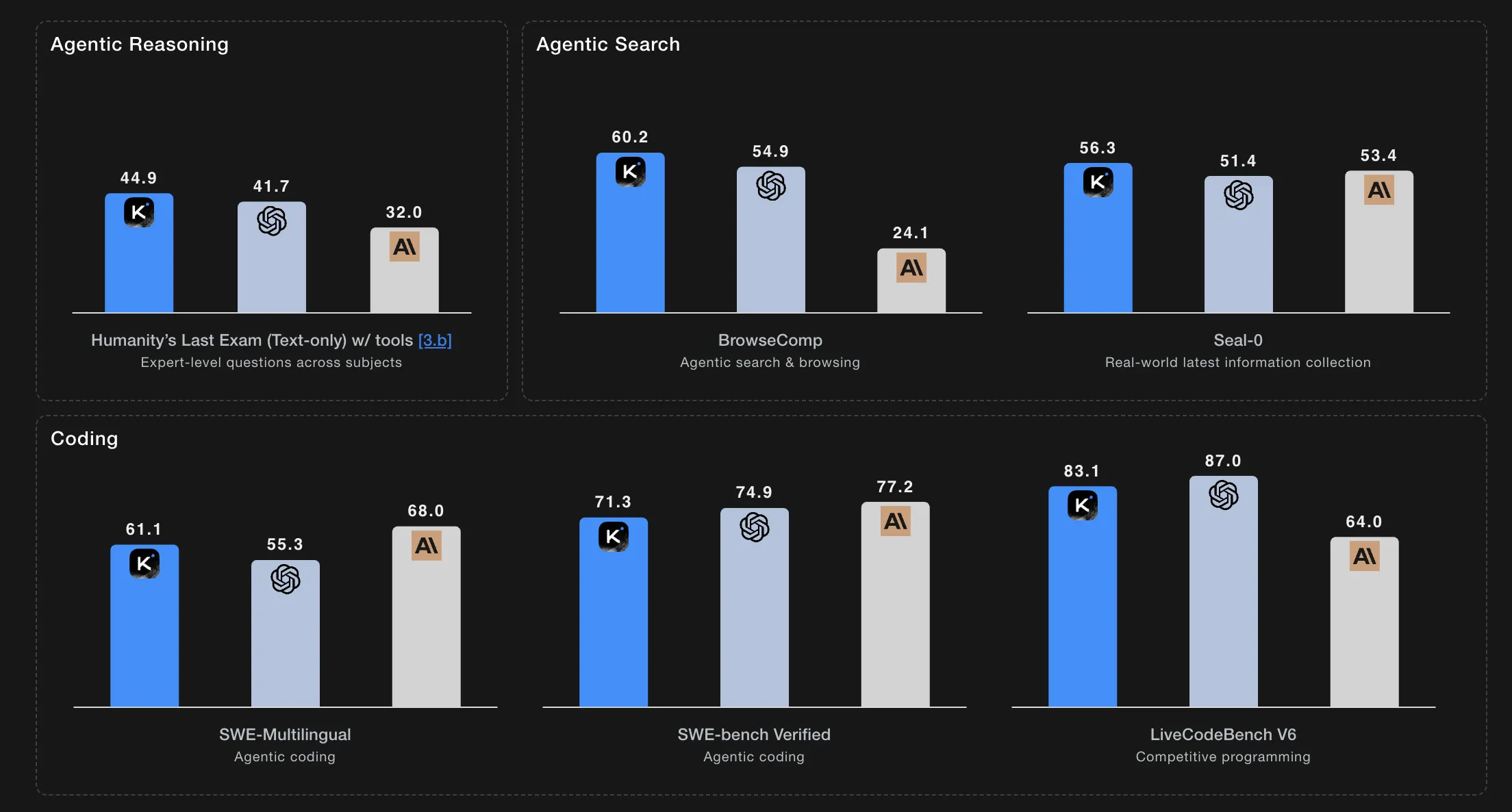
Setting new benchmarks, K2 Thinking excels on challenging tests such as Humanity’s Last Exam and BrowseComp, maintaining coherent and stable behavior through 200 to 300 consecutive tool interactions autonomously.
Notably, K2 Thinking is released with open weights, featuring an expansive 256,000-token context window and native INT4 quantization. This combination significantly reduces latency and GPU memory consumption while preserving top-tier benchmark results.
Currently accessible via chat on kimi.com and through the Moonshot platform API, a forthcoming agentic mode will fully unlock its tool-using capabilities.
Innovative Architecture: MoE Design and Extended Context Capacity
At its core, Kimi K2 Thinking builds upon the Kimi K2 Mixture of Experts architecture. The model boasts a trillion parameters in total, activating approximately 32 billion parameters per token during inference. Its deep network comprises 61 layers, including one dense layer and 384 experts, with eight experts selected per token alongside a shared expert. The attention mechanism employs 64 heads with a hidden dimension of 7,168, while each expert’s hidden dimension is 2,048.
The vocabulary encompasses 160,000 tokens, and the model supports an unprecedented context length of 256,000 tokens. It utilizes Multi-Head Latent Attention and the SwiGLU activation function to enhance performance and efficiency.
Scaling Reasoning Depth: Test-Time Adaptability and Long-Horizon Planning
Kimi K2 Thinking is explicitly engineered for scalable reasoning during inference. Unlike models constrained to fixed-length thought chains, it dynamically extends its reasoning and tool invocation depth in response to task complexity.

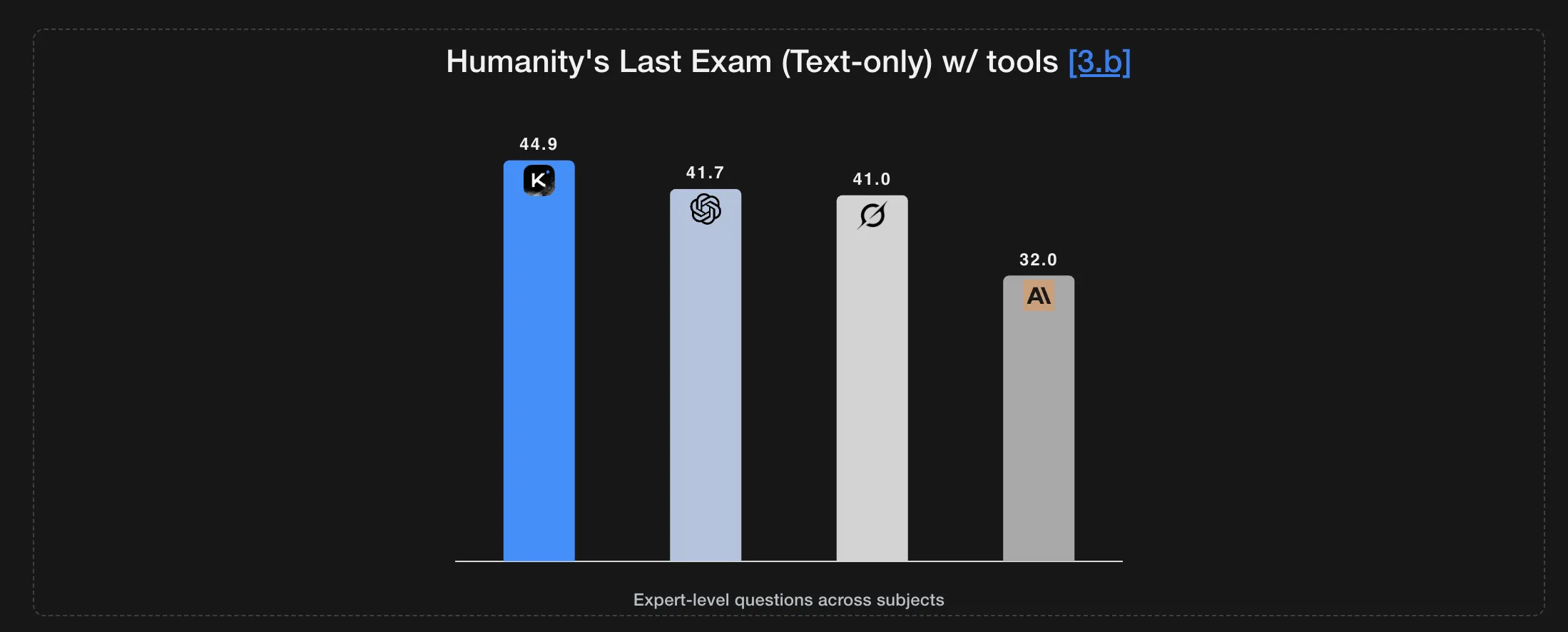
Performance highlights include a score of 23.9 on Humanity’s Last Exam (HLE) without tool assistance, which jumps to 44.9 with tools and peaks at 51.0 under intensive conditions. On mathematical reasoning benchmarks, it achieves 99.1 on AIME25 and 95.1 on HMMT25 using Python. It also scores 78.6 on IMO AnswerBench and 84.5 on GPQA.
Testing protocols allocate substantial token budgets: 96,000 tokens for HLE, AIME25, HMMT25, and GPQA; 128,000 tokens for IMO AnswerBench, LiveCodeBench, and OJ Bench; and 32,000 tokens for Longform Writing completions. Step limits vary by task, with up to 120 steps and 48,000 reasoning tokens per step on HLE, and up to 300 steps with 24,000 tokens per step on agentic search tasks.
Benchmark Excellence in Agentic Search and Programming
In agentic search scenarios utilizing tools, K2 Thinking achieves impressive results: 60.2 on BrowseComp, 62.3 on BrowseComp ZH (Chinese), 56.3 on Seal 0, 47.4 on FinSearchComp T3, and 87.0 on Frames.
On general knowledge assessments, it scores 84.6 on MMLU Pro, 94.4 on MMLU Redux, 73.8 on Longform Writing, and 58.0 on HealthBench.
For coding challenges, the model attains 71.3 on SWE Bench Verified with tools, 61.1 on SWE Bench Multilingual with tools, 41.9 on Multi SWE Bench with tools, 44.8 on SciCode, 83.1 on LiveCodeBenchV6, 48.7 on OJ Bench (C++), and 47.1 on Terminal Bench with simulated tools.
Moonshot AI also introduces a Heavy Mode, which runs eight parallel reasoning trajectories and aggregates their outputs to enhance accuracy on complex benchmarks.
Efficient Deployment: Native INT4 Quantization and Inference
K2 Thinking is trained with native INT4 quantization, employing Quantization Aware Training during post-training to optimize performance. This approach applies INT4 weight-only quantization specifically to the MoE components, enabling approximately double the generation speed in low-latency inference modes without sacrificing accuracy.
All benchmark results are reported under INT4 precision. Model checkpoints are stored in compressed tensor formats, which can be decompressed to higher precision formats like FP8 or BF16 using official tools. Recommended inference engines include vLLM, SGLang, and KTransformers for optimal performance.
Summary of Key Features and Advantages
- Open-Source Thinking Agent: Kimi K2 Thinking extends the Kimi K2 MoE architecture to support explicit long-horizon reasoning and tool integration, moving beyond simple conversational responses.
- Massive Scale and Context: Utilizes a trillion-parameter MoE design with tens of billions of active parameters per token and a 256K token context window, trained with native INT4 quantization for efficient inference.
- Adaptive Reasoning Depth: Optimized for test-time scaling, capable of executing hundreds of sequential tool calls within a single task, evaluated under large token budgets and strict step limits to ensure reproducibility.
- Benchmark Leadership: Demonstrates top-tier or competitive performance across reasoning, agentic search, and coding benchmarks, including Humanity’s Last Exam with tools, BrowseComp, and SWE Bench Verified with tools.
Final Thoughts
Kimi K2 Thinking marks a significant milestone in the evolution of open-source AI reasoning models, emphasizing test-time scalability as a core design principle. Moonshot AI’s release of a trillion-parameter MoE system with 32 billion active parameters, a 256K token context window, and native INT4 quantization showcases the feasibility of deploying sophisticated reasoning agents capable of extended planning and tool use in real-world scenarios. This development signals a shift from experimental prototypes to practical, high-performance AI infrastructure.





{kind=link}