

Liquid AI has introduced LFM2-Audio-1.5B, a streamlined audio-language foundation model designed to seamlessly comprehend and generate both speech and text within a unified, end-to-end architecture. Tailored for devices with limited computational resources, this model aims to deliver ultra-low latency performance, making it ideal for real-time voice assistants. This release marks the expansion of the LFM2 series into the audio domain while maintaining a compact model size.

Innovative Unified Architecture with Distinct Audio Input and Output Processing
The LFM2-Audio model builds upon the 1.2 billion parameter LFM2 language backbone, treating audio and text as equally important sequential tokens. A key innovation lies in its decoupling of audio input and output representations: the model ingests continuous embeddings derived directly from raw audio waveform segments of approximately 80 milliseconds, while its outputs are generated as discrete audio tokens. This approach eliminates the common discretization distortions on the input side and preserves autoregressive generation for both audio and text on the output side, enhancing quality and coherence.
Technical Specifications of the Released Model
- Core Backbone: LFM2 hybrid architecture combining convolutional layers and attention mechanisms, with 1.2 billion parameters dedicated to language modeling.
- Audio Encoder: FastConformer model (~115 million parameters), optimized for efficient audio feature extraction.
- Audio Decoder: RQ-Transformer that predicts discrete tokens from the Mimi codec, utilizing 8 distinct codebooks.
- Context Window: Supports up to 32,768 tokens.
- Vocabulary Size: 65,536 tokens for text; 2049 tokens per codebook for audio, multiplied by 8 codebooks.
- Precision: bfloat16 format for efficient computation.
- License: Distributed under LFM Open License v1.0.
- Supported Language: English.
Dual Generation Modes Optimized for Interactive Voice Applications
LFM2-Audio supports two distinct generation strategies to cater to different real-time voice interaction scenarios:
- Interleaved Generation: Designed for live speech-to-speech conversations, this mode alternates between generating text and audio tokens to minimize latency and enhance the fluidity of dialogue.
- Sequential Generation: Suitable for automatic speech recognition (ASR) and text-to-speech (TTS) tasks, this mode switches between modalities in a turn-by-turn fashion.
Developers can experiment with these capabilities through the provided Python package liquid-audio and an interactive Gradio demo.
Exceptional Responsiveness: Sub-100 Millisecond Latency
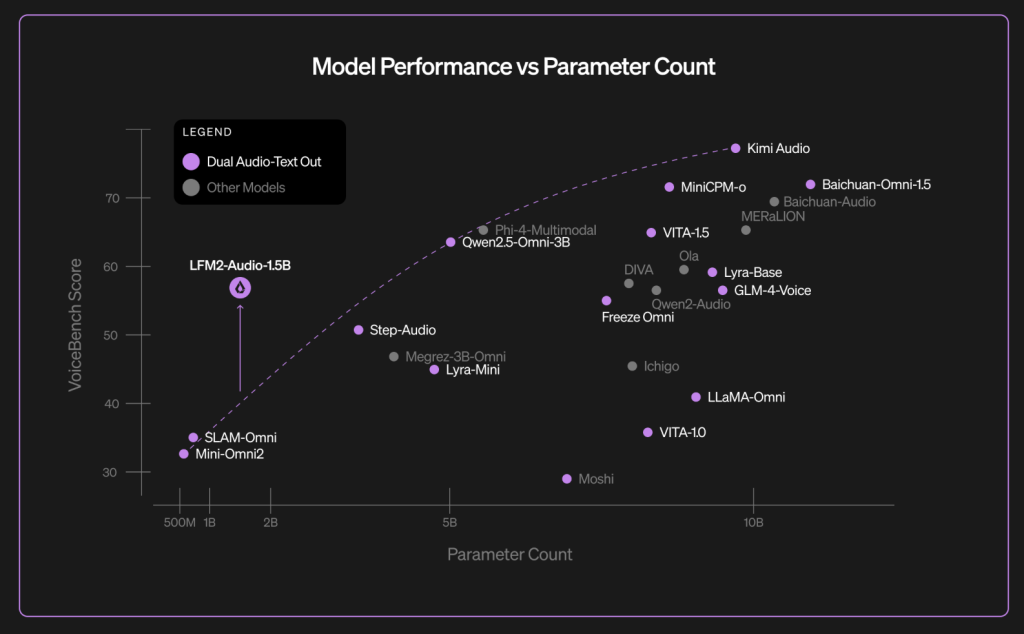
Liquid AI reports that LFM2-Audio achieves an impressive end-to-end latency of less than 100 milliseconds from the moment a 4-second audio input is received to the first audible output. This rapid response time significantly enhances user experience in conversational AI, outperforming other models with fewer than 1.5 billion parameters under comparable conditions.
Performance Benchmarks: VoiceBench and ASR Accuracy
On VoiceBench, a comprehensive benchmark suite comprising nine audio assistant evaluation tasks introduced in late 2024, LFM2-Audio-1.5B attained an overall score of 56.78. Detailed task-specific results include scores such as AlpacaEval at 3.71, CommonEval at 3.49, and WildVoice at 3.17. These results are competitive when compared to larger models like Qwen2.5-Omni-3B and Moshi-7B.
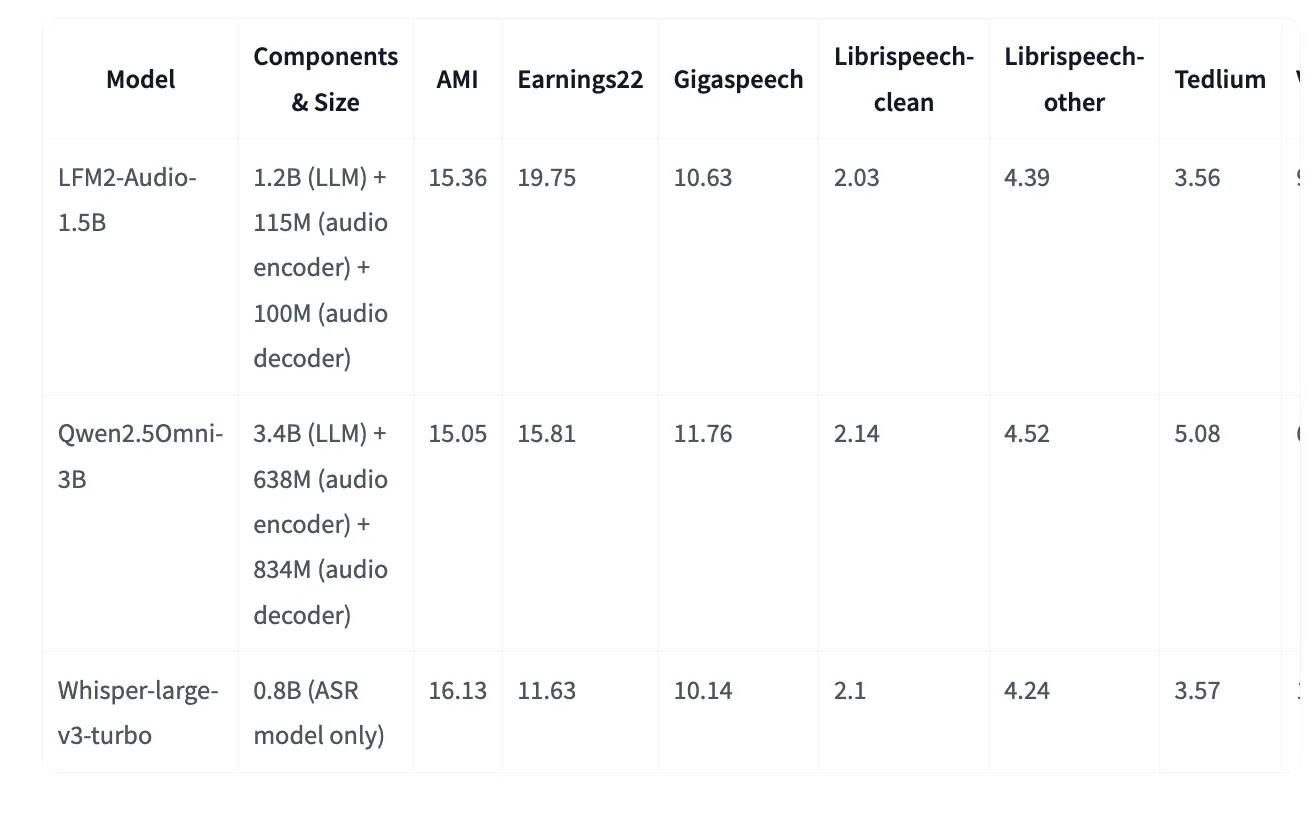
Additionally, the model’s Hugging Face card presents further VoiceBench metrics and classic ASR word error rates (WERs), where LFM2-Audio matches or surpasses Whisper-large-v3-turbo on several datasets. For instance, it achieves a WER of 15.36 on the AMI dataset versus 16.13 for Whisper, and 2.03 on LibriSpeech-clean compared to Whisper’s 2.10, demonstrating its versatility as a generalist speech-text model.

Significance in the Evolving Landscape of Voice AI
Traditional “omni” voice AI systems typically chain together separate components for ASR, large language models (LLMs), and TTS, which often results in increased latency and fragile integration points. LFM2-Audio’s innovative single-backbone framework, featuring continuous audio inputs and discrete audio outputs, streamlines this pipeline by reducing intermediary processing layers. This design enables interleaved decoding, allowing the model to emit audio outputs earlier and thus improve perceived responsiveness.
For developers, this translates into simpler system architectures and faster interactive experiences, all while supporting a broad range of functionalities including ASR, TTS, classification, and conversational agents within a single model. Liquid AI facilitates adoption by providing accessible codebases, demo interfaces, and distribution through Hugging Face.






{kind=link}