
Introducing Apriel-1.5-15B-Thinker: A Breakthrough in Multimodal AI Reasoning
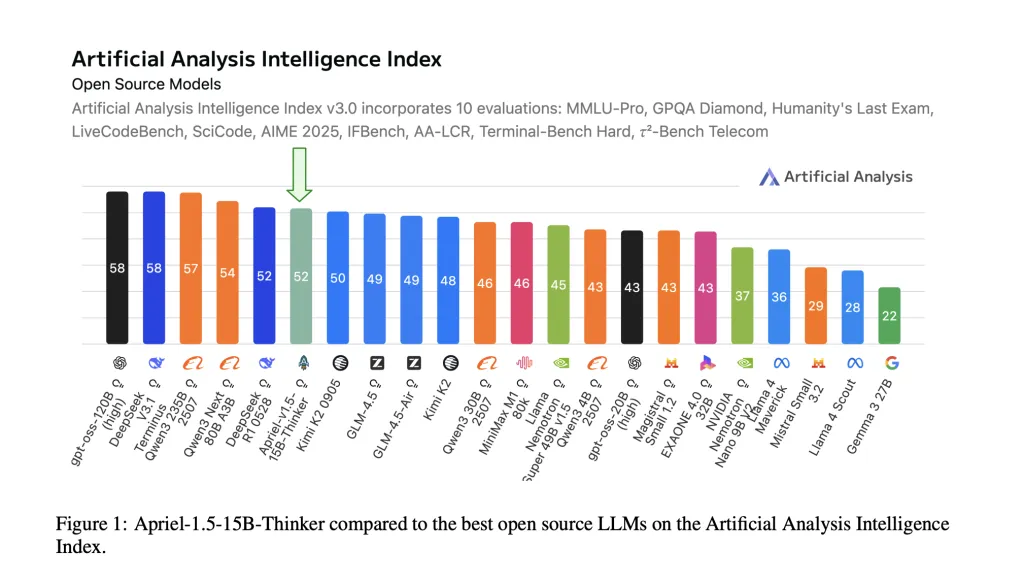
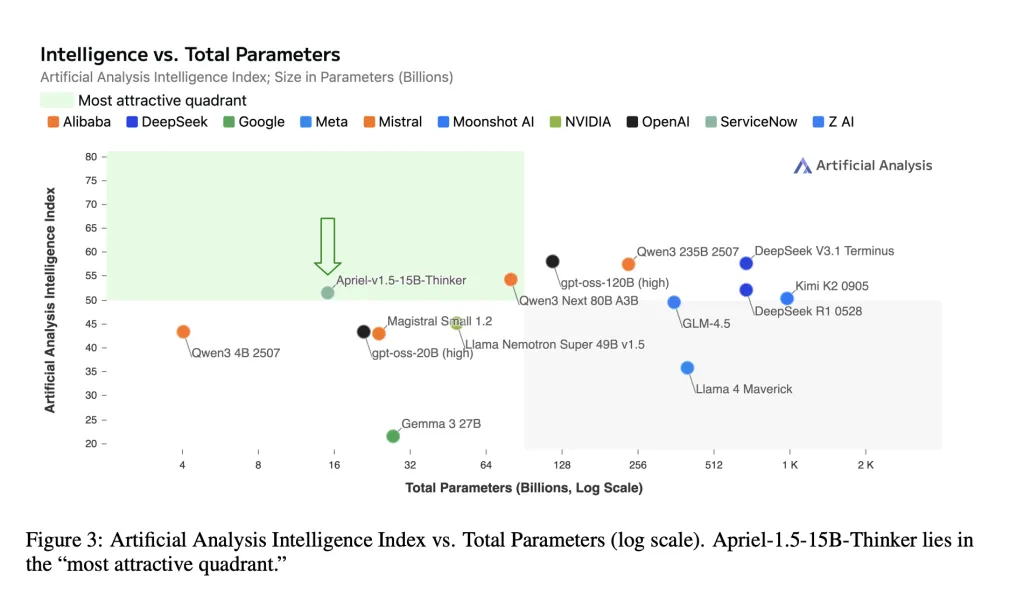
ServiceNow AI Research Lab has unveiled Apriel-1.5-15B-Thinker, an advanced multimodal reasoning model featuring 15 billion parameters with fully open weights. This model is developed using a data-centric mid-training approach-combining continual pretraining with supervised fine-tuning-without relying on reinforcement learning or preference optimization techniques. Impressively, Apriel-1.5-15B-Thinker achieves an Artificial Analysis Intelligence Index (AAI) score of 52, delivering this performance at an 8-fold reduction in cost compared to state-of-the-art alternatives. The model checkpoint and training pipeline are publicly accessible, promoting transparency and reproducibility.
What Makes Apriel-1.5-15B-Thinker Stand Out?
- Frontier-Level Performance at a Compact Scale: Despite its relatively modest size, Apriel-1.5-15B-Thinker matches the AAI score of 52, comparable to the larger DeepSeek-R1-0528 model. The AAI metric synthesizes results from 10 rigorous third-party benchmarks, including MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME 2025, IFBench, AA-LCR, Terminal-Bench Hard, and τ²-Bench Telecom.
- Optimized for Single-GPU Deployment: The model’s 15-billion-parameter checkpoint is designed to fit within the memory constraints of a single GPU, making it ideal for on-premises environments and secure, air-gapped systems where latency and fixed memory budgets are critical.
- Fully Open and Verifiable: All model weights, training methodologies, and evaluation protocols are openly shared, enabling independent validation and fostering community-driven improvements.
Innovative Training Strategy Behind Apriel-1.5-15B-Thinker
Foundation and Model Scaling: The architecture builds upon Mistral’s Pixtral-12B-Base-2409 multimodal decoder-vision framework. The team enhanced the model’s depth by increasing decoder layers from 40 to 48, followed by a projection-network realignment to synchronize the vision encoder with the expanded decoder. This approach circumvents the need for training from scratch while maintaining the model’s compatibility with single-GPU deployment.
Continual Pretraining (CPT): The pretraining phase is split into two key stages. First, the model is exposed to a diverse mixture of text and image data to develop foundational reasoning skills and improve comprehension of documents and diagrams. Second, it undergoes targeted synthetic visual tasks such as image reconstruction, matching, object detection, and counting to refine spatial and compositional reasoning abilities. Sequence lengths are extended up to 32,000 tokens for the initial stage and 16,000 tokens for the latter, with selective loss application focused on response tokens in instruction-formatted samples.
Supervised Fine-Tuning (SFT): The fine-tuning process leverages high-quality instruction datasets emphasizing reasoning traces across domains like mathematics, programming, scientific inquiry, and tool usage. Two additional fine-tuning passes-one on a stratified subset and another on longer-context samples-are combined through weight merging to produce the final model checkpoint. Notably, this process excludes reinforcement learning or AI feedback-based optimization.
Performance Highlights and Benchmark Results
Apriel-1.5-15B-Thinker demonstrates strong results across a variety of challenging benchmarks, including:
- AIME 2025 (American Invitational Mathematics Examination): Achieves an accuracy of approximately 87.5-88%, showcasing robust mathematical reasoning.
- GPQA Diamond (Graduate-Level Google-Proof Question Answering): Scores near 71%, reflecting advanced question-answering capabilities.
- IFBench (Instruction-Following Benchmark): Reaches around 62% accuracy, indicating strong adherence to complex instructions.
- τ²-Bench Telecom: Attains roughly 68%, demonstrating competence in telecom-related reasoning tasks.
- LiveCodeBench (Functional Code Correctness): Scores approximately 72.8%, highlighting proficiency in code generation and validation.
Using the VLMEvalKit for standardized evaluation, Apriel also performs competitively on multimodal and multidisciplinary datasets such as MMMU / MMMU-Pro, LogicVista, MathVision, MathVista, MathVerse, MMStar, CharXiv, AI2D, and BLINK. The model particularly excels in interpreting documents, diagrams, and math-heavy textual imagery.
Summary: Why Apriel-1.5-15B-Thinker Matters
Apriel-1.5-15B-Thinker exemplifies how a meticulously designed mid-training regimen-combining continual pretraining with supervised fine-tuning and excluding reinforcement learning-can yield frontier-level AI reasoning performance while remaining resource-efficient. Its AAI score of 52, coupled with strong task-specific accuracies (e.g., ~88% on AIME 2025 and ~71% on GPQA Diamond), positions it among the most cost-effective open-weight models available today.
For organizations seeking a powerful yet deployable AI reasoning system, Apriel offers a compelling option: open-source weights, a transparent and reproducible training pipeline, and the ability to run on a single GPU. This makes it an excellent baseline for enterprises to benchmark before investing in larger, proprietary AI solutions.

{kind=link}