
Evaluating AI-Generated Scientific Summaries: A Critical Review
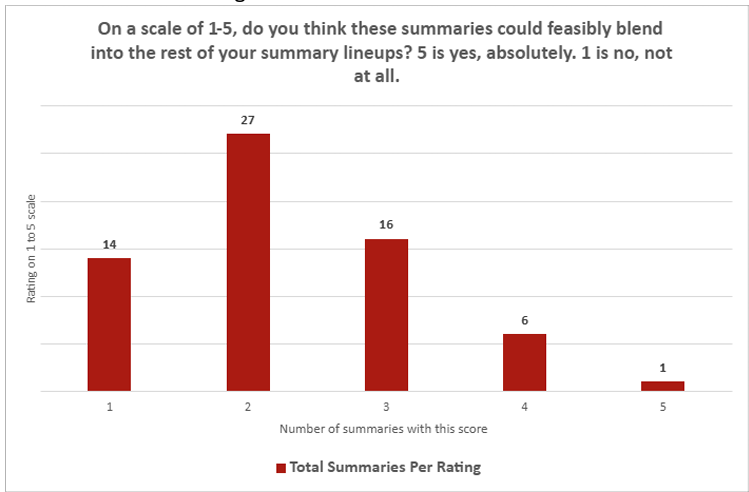
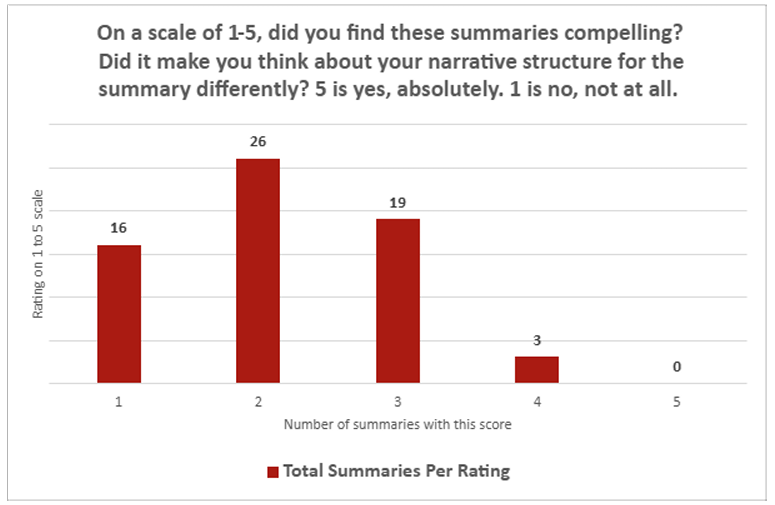
Recent assessments of AI-generated summaries, particularly those produced by ChatGPT, reveal significant challenges in their ability to match human-crafted scientific briefs. Journalists involved in the evaluation rated these AI summaries quite low in terms of integration and engagement. On a scale from 1 (“not at all”) to 5 (“absolutely”), the average score for how well ChatGPT summaries could seamlessly fit into existing summary collections was only 2.26. Similarly, when asked if the summaries were compelling, the average rating dropped slightly to 2.14. Notably, only one summary received the highest rating of 5, while a striking 30 summaries were rated at the lowest level of 1.
Shortcomings in Accuracy and Contextual Understanding
Beyond numerical ratings, qualitative feedback from writers highlighted several recurring issues. A common criticism was ChatGPT’s tendency to confuse correlation with causation, a fundamental error in scientific interpretation. Additionally, the AI often omitted crucial contextual details-for example, failing to mention that soft actuators typically operate at slower speeds. Another frequent problem was the overuse of exaggerated descriptors such as “groundbreaking” and “novel,” which inflated the significance of findings. Interestingly, this tendency diminished when prompts explicitly instructed the AI to avoid such language.
Overall, the AI demonstrated competence in accurately “transcribing” straightforward scientific content, especially from papers lacking complex nuances. However, it struggled with “translating” the research-delving into experimental methods, acknowledging limitations, or discussing broader implications. These weaknesses were particularly evident when summarizing studies with conflicting results or when tasked with condensing multiple related papers into a single concise summary.
Style Alignment but Persistent Factual Concerns
While the tone and style of ChatGPT’s outputs often mirrored human-written summaries, concerns about factual reliability were widespread among the journalists. Many noted that even using AI-generated summaries as a foundation for human editing demanded equal or greater effort compared to writing summaries from scratch. This was primarily due to the extensive fact-checking required to verify the AI’s content.
These findings align with earlier research indicating that AI-driven search tools can reference inaccurate news sources up to 60% of the time. Such inaccuracies are especially problematic in scientific communication, where precision and clarity are essential.
Future Prospects and Ongoing Developments
Ultimately, the evaluation concluded that ChatGPT’s current capabilities fall short of the rigorous style and quality standards expected for scientific press packages. However, the researchers acknowledged the potential value of revisiting this experiment following significant AI model updates. Notably, the release of GPT-5 in August 2025 may offer improvements that address some of these limitations.

{kind=link}