In this article, I present a novel reinforcement learning (RL) approach grounded in a distinctive framework: divide and conquer. Diverging from conventional techniques, this method does not rely on temporal difference (TD) learning, which often faces challenges with long-horizon tasks, and instead offers a scalable alternative.

Reinforcement Learning can be effectively approached through divide and conquer, bypassing traditional temporal difference learning.
Understanding Off-Policy Reinforcement Learning
Our focus is on off-policy reinforcement learning, a setting that allows the use of diverse data sources beyond the current policy’s experience.
Reinforcement learning algorithms generally fall into two categories: on-policy and off-policy. On-policy methods, such as PPO and GRPO, require fresh data generated by the current policy, discarding previous experiences after each update. This constraint limits data reuse and can be inefficient.
In contrast, off-policy RL methods can leverage any available data, including past experiences, human demonstrations, or even internet-sourced datasets. This flexibility makes off-policy RL particularly valuable in domains where data collection is costly or risky, such as robotics, healthcare, and conversational AI.
Despite advances in scaling on-policy algorithms, as of 2025, developing off-policy RL algorithms that efficiently handle complex, long-duration tasks remains an open challenge. The difficulty largely stems from the way value functions are learned and updated.
Value Learning Paradigms: Temporal Difference vs. Monte Carlo
Traditionally, off-policy RL employs temporal difference (TD) learning, exemplified by Q-learning, which updates value estimates using the Bellman equation:
Q(s, a) ← r + γ maxa' Q(s', a')
However, TD learning suffers from error propagation: inaccuracies in the estimated value of the next state-action pair accumulate over time, especially in tasks with long horizons, leading to instability and poor performance.
To alleviate this, hybrid methods like n-step TD learning incorporate Monte Carlo (MC) returns for the initial steps before bootstrapping, reducing error accumulation by limiting the depth of recursive updates:
Q(st, at) ← ∑i=0n-1 γi rt+i + γn maxa' Q(st+n, a')
While this approach mitigates some issues, it introduces new challenges: selecting the optimal n is non-trivial, and larger n values increase variance and can degrade performance. Fundamentally, error accumulation is only reduced linearly, not eliminated.
Is there a fundamentally different strategy that can overcome these limitations?
Introducing the Divide-and-Conquer Paradigm in Value Learning
The divide and conquer paradigm offers a promising alternative by recursively splitting trajectories into smaller segments and combining their values to estimate the value of the entire trajectory. This approach reduces the number of Bellman recursions logarithmically rather than linearly, potentially enabling better scalability to long-horizon tasks.
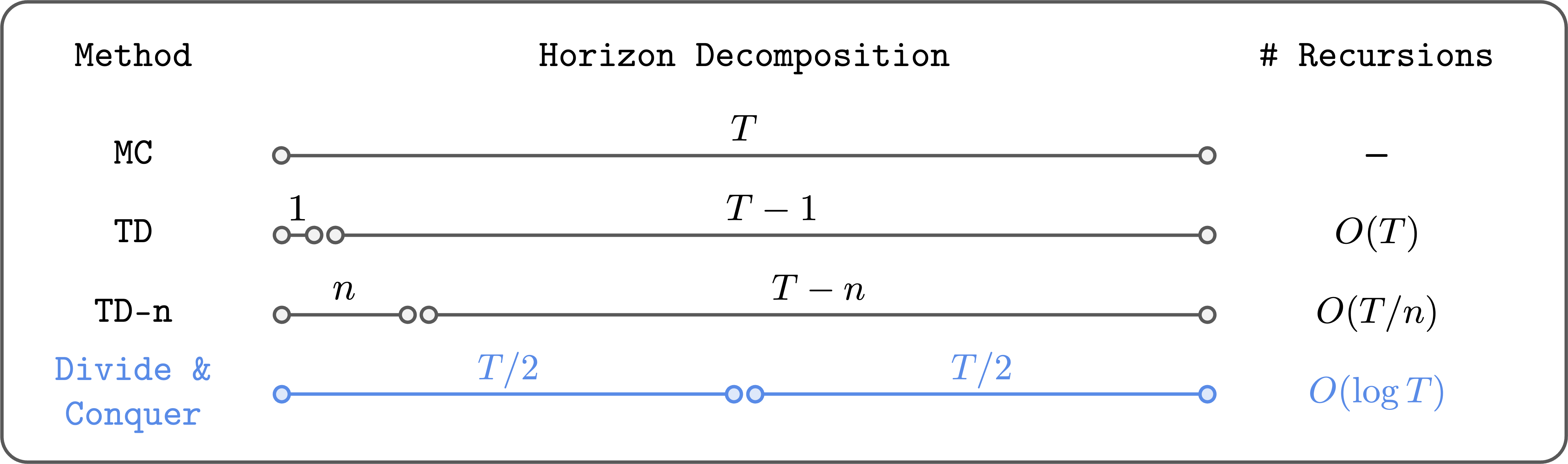
Divide and conquer significantly decreases the depth of recursive value updates, enhancing scalability.
Unlike n-step TD, this method does not require tuning a trajectory length hyperparameter and avoids the high variance associated with large n-step returns. Conceptually, it embodies the ideal properties for value learning, but practical implementation has historically been elusive.
Realizing Divide-and-Conquer: A Practical Algorithm for Goal-Conditioned RL
Recent work has made strides in operationalizing divide-and-conquer value learning, particularly within the domain of goal-conditioned reinforcement learning. This setting involves learning policies capable of reaching arbitrary goal states from any starting state, naturally lending itself to recursive decomposition.
Assuming deterministic dynamics, the shortest path distance between states, denoted as d*(s, g), satisfies the triangle inequality:
d*(s, g) ≤ d*(s, w) + d*(w, g)
for any intermediate state w. Translating this into value function terms yields a transitive Bellman update:
V(s, g) ←
{
1,
