
OpenAI has introduced a research preview featuring two open-weight safety reasoning models designed to empower developers with the ability to enforce customized safety policies dynamically during inference. These models, available in two configurations, are both fine-tuned versions of gpt-oss, released under the Apache 2.0 license, and accessible on Hugging Face for local deployment.
The Importance of Policy-Driven Safety Mechanisms
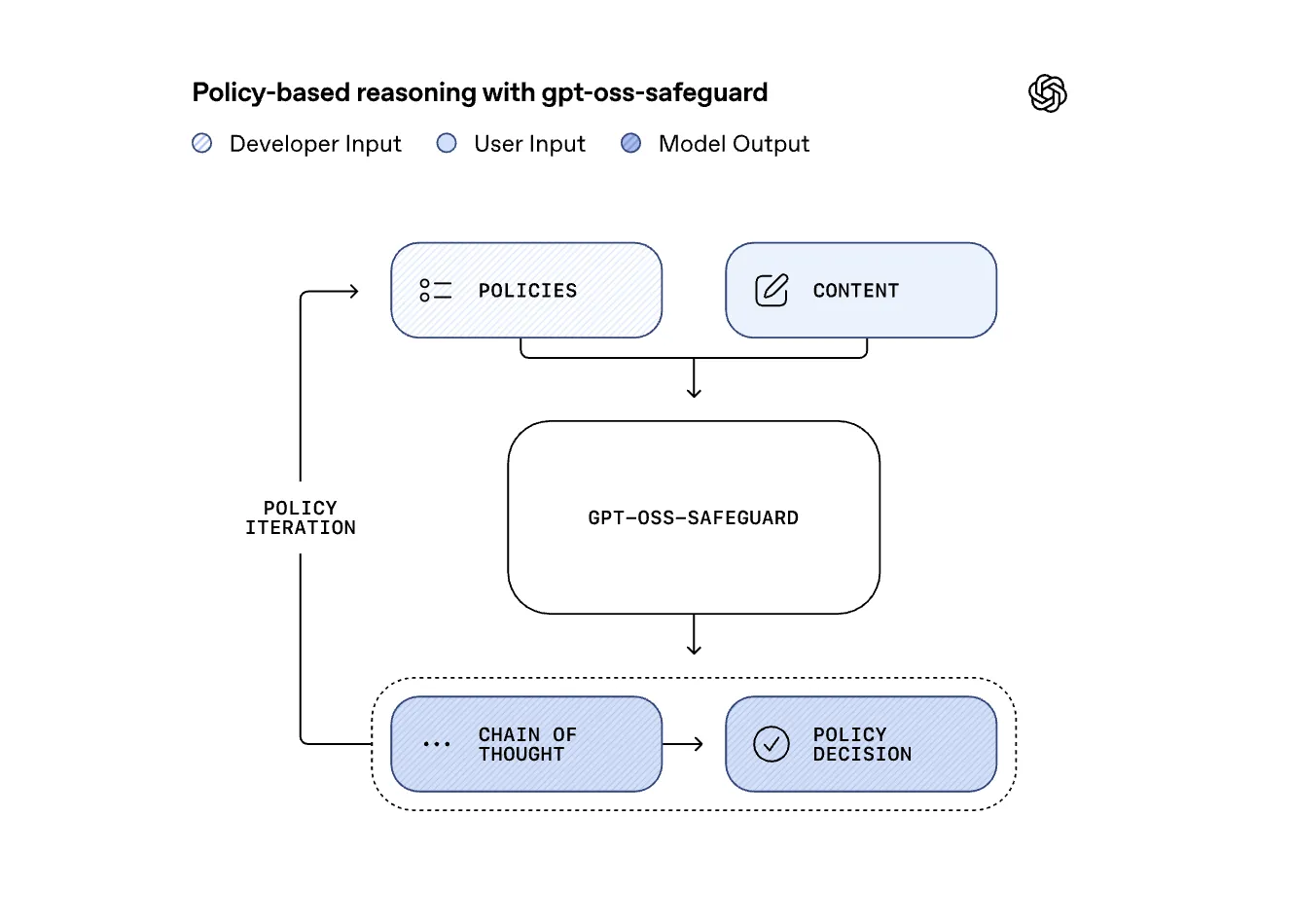
Traditional content moderation systems rely on a fixed policy framework, necessitating retraining or replacement whenever policies evolve. In contrast, the gpt-oss-safeguard models invert this paradigm by accepting developer-defined policies as input alongside user content. They then perform stepwise reasoning to determine if the content breaches the specified guidelines. This approach transforms safety enforcement into a flexible prompt-based evaluation, making it particularly effective for rapidly changing or niche domains such as cybersecurity fraud detection, biomedical content moderation, self-harm prevention, or moderation in specialized gaming communities.
Mirroring OpenAI’s Internal Safety Reasoning Architecture
OpenAI reveals that gpt-oss-safeguard is an open-weight counterpart to the Safety Reasoner technology deployed internally across flagship systems like GPT-5, ChatGPT Agent, and Sora 2. In operational environments, OpenAI employs a tiered safety strategy: lightweight, high-recall filters first screen all inputs, escalating ambiguous or sensitive cases to a more computationally intensive reasoning model. Notably, recent deployments have allocated up to 16% of total compute resources to safety reasoning. By releasing these models publicly, OpenAI enables external developers to replicate this robust, layered defense mechanism rather than relying on speculation about internal workflows.
Model Variants and Hardware Compatibility
The larger variant, gpt-oss-safeguard-120b, comprises 117 billion parameters with 5.1 billion active parameters during inference, optimized to run on a single 80GB NVIDIA H100 GPU. The smaller gpt-oss-safeguard-20b contains 21 billion parameters and 3.6 billion active parameters, targeting lower latency scenarios and compatibility with more modest hardware, including GPUs with 16GB of memory. Both models are fine-tuned using the harmony response format, which requires prompts to adhere to this structure to maintain optimal performance. The Apache 2.0 license permits commercial use and local deployment, offering flexibility for enterprise applications.

Performance Assessment and Benchmarking
OpenAI conducted extensive evaluations of these models using both proprietary multi-policy test suites and publicly available datasets. In scenarios requiring simultaneous application of multiple policies, gpt-oss-safeguard and OpenAI’s internal Safety Reasoner outperformed both the gpt-5-thinking model and baseline gpt-oss models. On the 2022 moderation benchmark, the new models showed a slight edge over gpt-5-thinking and the internal Safety Reasoner, though OpenAI cautions that this difference lacks statistical significance and should be interpreted conservatively. On the ToxicChat dataset, the internal Safety Reasoner maintained a lead, with gpt-oss-safeguard closely trailing, positioning these open models as competitive options for real-world moderation challenges.
Optimal Deployment Strategies for Safety Reasoning
Given the computational expense of running reasoning models on every input, OpenAI advises a hybrid moderation pipeline. This involves deploying fast, lightweight classifiers to filter the majority of content, reserving the gpt-oss-safeguard models for ambiguous or high-risk cases. For applications demanding rapid user feedback, the reasoning step can be executed asynchronously to balance safety with responsiveness. This layered approach aligns with OpenAI’s production best practices and acknowledges that specialized classifiers remain advantageous when supported by extensive, high-quality labeled datasets.
Summary of Core Insights
- gpt-oss-safeguard introduces two open-weight safety reasoning models (120b and 20b) that enable dynamic content classification based on developer-defined policies, eliminating the need for retraining when policies change.
- These models replicate the Safety Reasoner framework used internally by OpenAI across major products, employing a fast initial filter followed by a detailed reasoning stage for uncertain content.
- Both models are fine-tuned from gpt-oss, maintain the harmony response format, and are engineered for practical deployment: the 120b model runs on a single H100 GPU, while the 20b model supports 16GB-class hardware, all under an Apache 2.0 license on Hugging Face.
- Evaluation on multi-policy and moderation datasets shows these models outperform gpt-5-thinking and gpt-oss baselines, though improvements over the internal Safety Reasoner are modest and not statistically significant.
- OpenAI recommends integrating these models within a multi-layered moderation system, complemented by community-driven tools like ROOST, to allow platforms to define custom taxonomies, audit reasoning processes, and update policies without modifying model weights.
Final Thoughts
This release marks a significant step in democratizing advanced safety reasoning by making OpenAI’s internal methodology accessible and reproducible. The open-weight, policy-conditioned design under an Apache 2.0 license empowers organizations to tailor moderation frameworks to their unique needs rather than relying on static, one-size-fits-all solutions. While the performance gains over existing internal models are incremental, the practical usability and flexibility of gpt-oss-safeguard models make them a promising tool for evolving content safety challenges. The suggested layered deployment strategy further enhances their viability for real-world applications, balancing computational cost with robust safety enforcement.

{kind=link}