
Introducing Checkpoint-Engine: Revolutionizing Large Language Model Updates
MoonshotAI has unveiled checkpoint-engine, an open-source, streamlined middleware designed to tackle a critical challenge in deploying large language models (LLMs): swiftly refreshing model weights across thousands of GPUs without interrupting ongoing inference tasks.
Addressing the Challenges of Frequent Model Updates in Reinforcement Learning
This tool is especially tailored for environments involving reinforcement learning (RL) and reinforcement learning with human feedback (RLHF), where models undergo constant updates. Minimizing downtime in these scenarios is essential, as any delay directly reduces system throughput and efficiency.
Unprecedented Speed in Updating Massive LLMs
Checkpoint-engine achieves a remarkable feat by updating a 1-trillion parameter model distributed over thousands of GPUs in approximately 20 seconds. This is a dramatic improvement compared to conventional distributed inference systems, which often require several minutes to reload models of similar scale.
By accelerating update times by nearly an order of magnitude, checkpoint-engine significantly enhances the efficiency of large-scale model serving.
Key Techniques Behind the Speed
- Broadcast Updates: Optimized for static GPU clusters to disseminate weights rapidly.
- Peer-to-Peer (P2P) Transfers: Designed for dynamic clusters, enabling flexible and elastic scaling.
- Concurrent Communication and Memory Operations: Overlapping data transfer and memory copying to minimize latency.
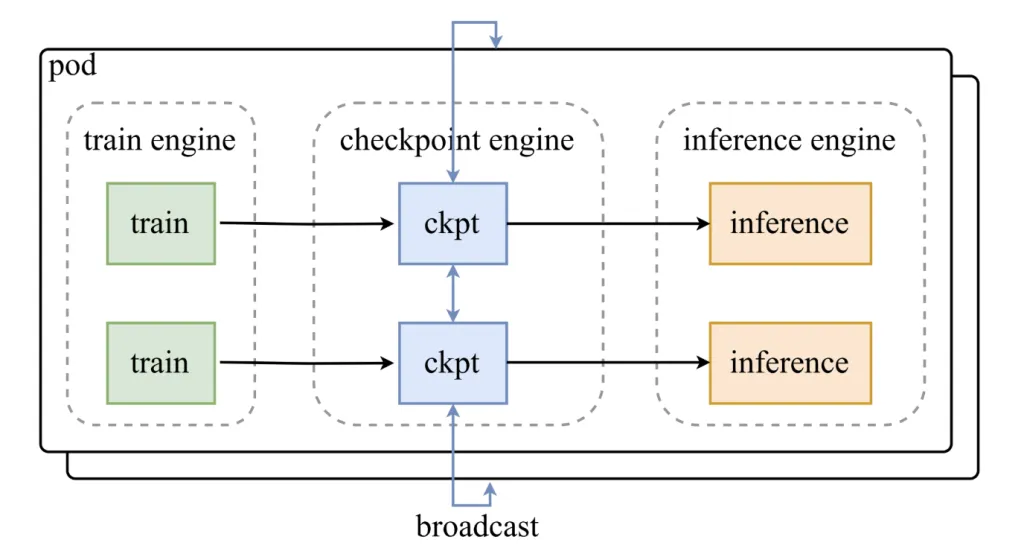
Architectural Insights: How Checkpoint-Engine Integrates with Existing Systems
Checkpoint-engine operates as an intermediary layer between training frameworks and inference clusters, orchestrating seamless weight updates without halting inference.
- Parameter Coordinator: Manages synchronization and update distribution.
- Worker Extensions: Plugins that integrate with inference engines like vLLM to facilitate efficient weight reloading.
Three-Phase Weight Update Pipeline
- Host-to-Device Transfer (H2D): Model parameters are loaded into GPU memory.
- Broadcast Distribution: Weights are shared across worker nodes using CUDA IPC buffers.
- Selective Reloading: Each inference shard updates only the necessary subset of weights.
This pipeline is engineered to maximize overlap between communication and computation, ensuring GPUs remain productive throughout the update process.
Real-World Performance Benchmarks
Extensive testing demonstrates checkpoint-engine’s scalability and efficiency across various models and hardware configurations:
- GLM-4.5-Air (BF16, 8× H800 GPUs): 3.94 seconds (broadcast), 8.83 seconds (P2P).
- Qwen3-235B-Instruct (BF16, 8× H800 GPUs): 6.75 seconds (broadcast), 16.47 seconds (P2P).
- DeepSeek-V3.1 (FP8, 16× H20 GPUs): 12.22 seconds (broadcast), 25.77 seconds (P2P).
- Kimi-K2-Instruct (FP8, 256× H20 GPUs): Approximately 21.5 seconds (broadcast), 34.49 seconds (P2P).
These results confirm that even at trillion-parameter scale with hundreds of GPUs, checkpoint-engine maintains rapid update cycles, meeting its design objectives.
Considerations and Limitations
While checkpoint-engine offers substantial benefits, users should be aware of certain trade-offs:
- Increased Memory Usage: The overlapping update pipeline demands extra GPU memory; insufficient memory triggers fallback mechanisms that slow down updates.
- Latency in Peer-to-Peer Mode: Although P2P updates enable cluster elasticity, they incur higher latency compared to broadcast methods.
- Limited Engine Compatibility: Currently, checkpoint-engine is officially supported only with vLLM; extending support to other inference engines requires additional development.
- Experimental Quantization Support: FP8 precision is supported but remains in an experimental phase, necessitating caution in production environments.
Ideal Use Cases for Checkpoint-Engine
This middleware is particularly advantageous in scenarios such as:
- Reinforcement Learning Workflows: Where models are updated frequently and downtime must be minimized.
- Large-Scale Inference Clusters: Handling models ranging from 100 billion to over 1 trillion parameters.
- Dynamic and Elastic Clusters: Environments requiring flexible scaling, where P2P updates provide adaptability despite some latency overhead.
Conclusion: A Step Forward in Continuous LLM Deployment
Checkpoint-engine offers a targeted and effective solution to the persistent challenge of synchronizing massive model weights rapidly without halting inference. By enabling trillion-parameter model updates in about 20 seconds and supporting both broadcast and peer-to-peer update modes, it paves the way for more efficient reinforcement learning pipelines and high-throughput inference systems.
Although currently limited to vLLM and with ongoing improvements needed in quantization and dynamic scaling, checkpoint-engine lays a solid foundation for continuous, large-scale model updates in production AI environments.

{kind=link}