
Is it possible for an open-source Mixture of Experts (MoE) model to efficiently drive agentic coding workflows at a fraction of the cost of leading flagship models, while maintaining robust long-term tool integration across multiple environments such as MCP, shell, browser, retrieval, and coding? The MiniMax team has unveiled MiniMax-M2, a specialized MoE model tailored for coding and agent-driven workflows. This model’s weights are openly available on Hugging Face under the MIT license. Designed for comprehensive tool utilization, multi-file editing, and extended planning horizons, MiniMax-M2 boasts 229 billion total parameters, with approximately 10 billion active per token. This selective activation strategy helps manage memory consumption and latency during iterative agent operations.
Understanding MiniMax-M2’s Architecture and the Importance of Activation Size
MiniMax-M2 is a streamlined MoE model that activates roughly 10 billion parameters per token, significantly reducing memory overhead and minimizing tail latency during the critical plan-act-verify cycles common in agent workflows. This efficient activation budget enables faster processing speeds and lower operational costs compared to dense models with similar performance levels, making it ideal for concurrent execution in continuous integration (CI), browsing, and retrieval pipelines.
One of the model’s unique features is its “interleaved thinking” mechanism. The development team encapsulates internal reasoning within <think>...</think> tags, instructing users to preserve these segments throughout multi-turn interactions. Omitting these reasoning blocks has been shown to degrade performance in complex, multi-step tasks and chained tool executions, underscoring their critical role in maintaining high-quality outputs.
Performance Benchmarks Focused on Coding and Agentic Tasks
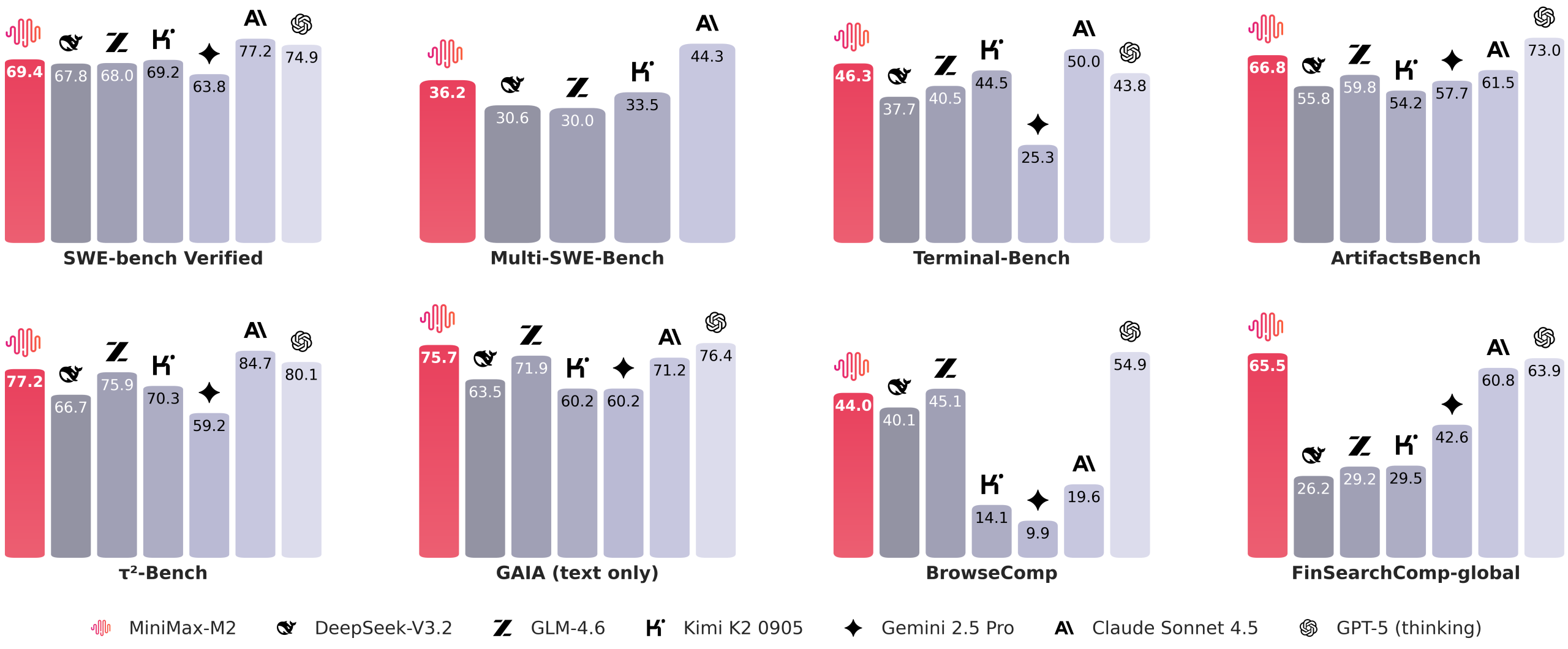
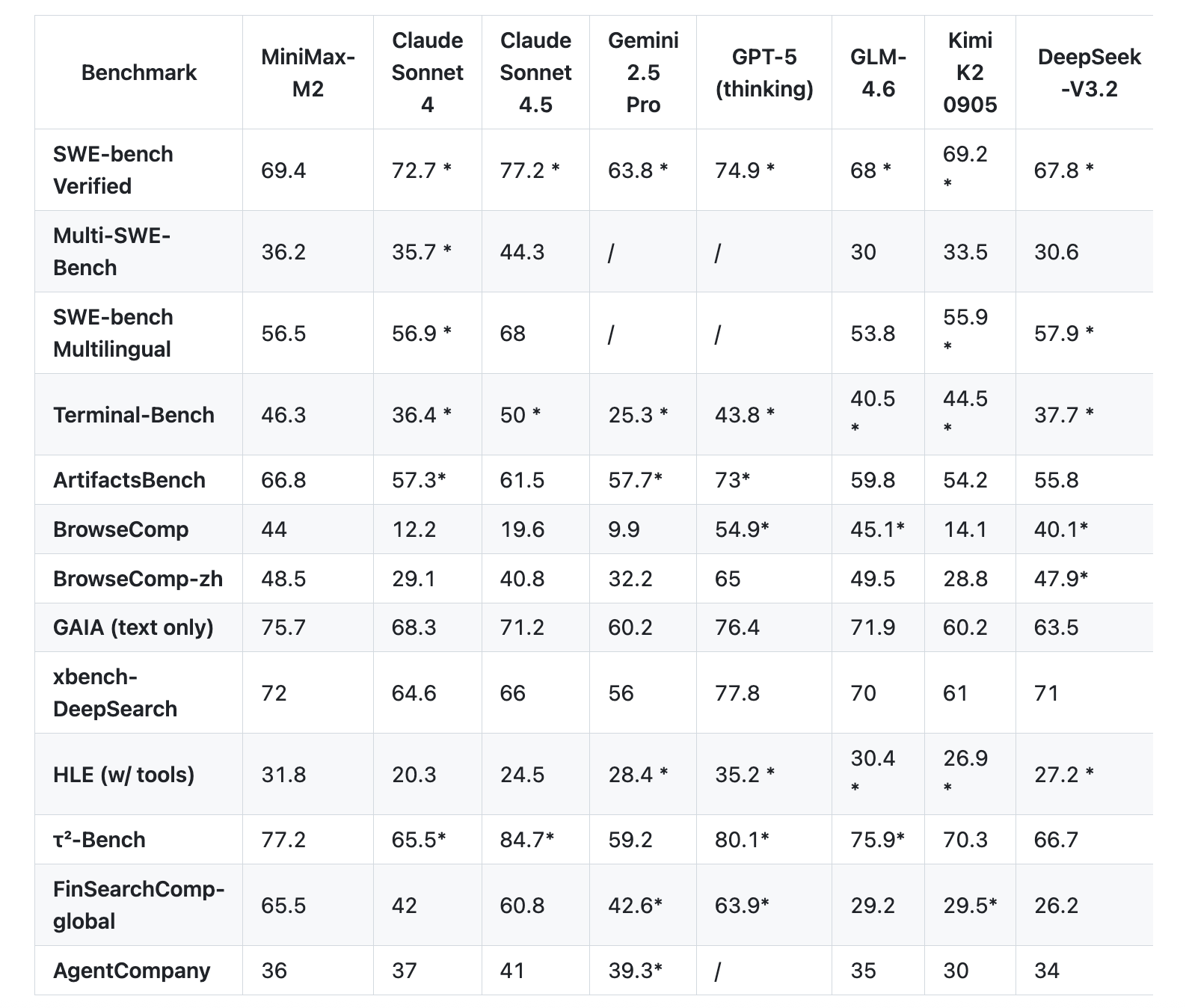
The MiniMax team emphasizes evaluations that mirror real-world developer workflows rather than static question-answering benchmarks. On the Terminal Bench, MiniMax-M2 achieves a score of 46.3, while on the Multi SWE Bench it records 36.2. The model scores 44.0 on BrowseComp and reaches 69.4 on the SWE Bench Verified, utilizing a scaffolded approach with OpenHands, supporting 128k context windows and up to 100-step reasoning chains. These results highlight the model’s strength in handling complex coding and agentic scenarios.
According to the official announcement, MiniMax-M2 operates at just 8% of the cost of Claude Sonnet, while delivering nearly twice the speed. The release also includes a limited-time free access period, with transparent token pricing and trial deadlines clearly outlined for users.
Comparing MiniMax M1 and M2: Evolution in Design and Capabilities
| Feature | MiniMax M1 | MiniMax M2 |
|---|---|---|
| Total Parameters | 456 billion | 229 billion (model card states 230B) |
| Active Parameters per Token | 45.9 billion | 10 billion |
| Core Architecture | Hybrid MoE with Lightning Attention | Sparse MoE optimized for coding and agent workflows |
| Reasoning Format | Thinking budget variants (40k and 80k tokens) in RL training; no mandatory think tags | Interleaved thinking with mandatory <think>...</think> tags preserved across turns |
| Benchmark Suites | AIME, LiveCodeBench, SWE-bench Verified, TAU-bench, long context MRCR, MMLU-Pro | Terminal-Bench, Multi SWE-Bench, SWE-bench Verified, BrowseComp, GAIA text-only, Artificial Analysis Intelligence suite |
| Default Inference Settings | Temperature 1.0, top-p 0.95 | Temperature 1.0, top-p 0.95, top-k 20-40 (varies by documentation) |
| Serving Recommendations | vLLM preferred; Transformers also supported | vLLM and SGLang recommended; includes detailed tool-calling guides |
| Primary Use Cases | Long-context reasoning, efficient test-time compute scaling, CISPO reinforcement learning | Native support for agentic and coding workflows across shell, browser, retrieval, and code execution |
Essential Insights and Highlights
- MiniMax-M2 is fully open-source with weights available on Hugging Face under the permissive MIT license, provided in safetensors format supporting FP32, BF16, and FP8 (F8_E4M3) precision.
- The model’s compact MoE design activates only about 10 billion parameters per token out of 229 billion total, enabling reduced memory usage and consistent latency during iterative agent planning and verification loops.
- Internal reasoning is explicitly wrapped in
<think>...</think>tags, which must be preserved in conversation histories to maintain performance in multi-step and tool-augmented tasks. - Benchmark results span multiple agent and coding-focused suites including Terminal-Bench, Multi SWE-Bench, and BrowseComp, with detailed scaffolding for reproducibility. Deployment guides for SGLang and vLLM are provided to facilitate immediate use.
Final Thoughts
MiniMax-M2 represents a significant advancement in open-source MoE models, delivering a balance of scale, efficiency, and specialized capabilities for agentic coding workflows. Its release under the MIT license with comprehensive deployment documentation and compatibility with popular serving frameworks like vLLM and SGLang makes it a compelling choice for developers and researchers seeking cost-effective, high-performance models. The model’s innovative interleaved thinking approach and optimized activation budget position it well for complex, multi-step tool use cases, setting a new standard for open-source AI in coding and agentic applications.

{kind=link}