
Revolutionizing Agent Training: Learning from Outcomes Without Rewards or Demonstrations
Imagine transforming your agent’s learning process so it trains solely from its own outcome-driven explorations-without relying on reward signals or expert demonstrations-yet still surpasses traditional imitation learning across multiple benchmarks. Meta Superintelligence Labs introduces an innovative framework called Early Experience, a reward-free training paradigm that enhances policy learning in language agents without the need for extensive human-labeled datasets or reinforcement learning loops. The principle is straightforward: the agent branches off from expert states, executes its own actions, observes the resulting future states, and uses these consequences as supervisory signals. This concept is realized through two novel techniques-Implicit World Modeling (IWM) and Self-Reflection (SR)-which consistently improve performance across eight diverse environments and various foundational models.
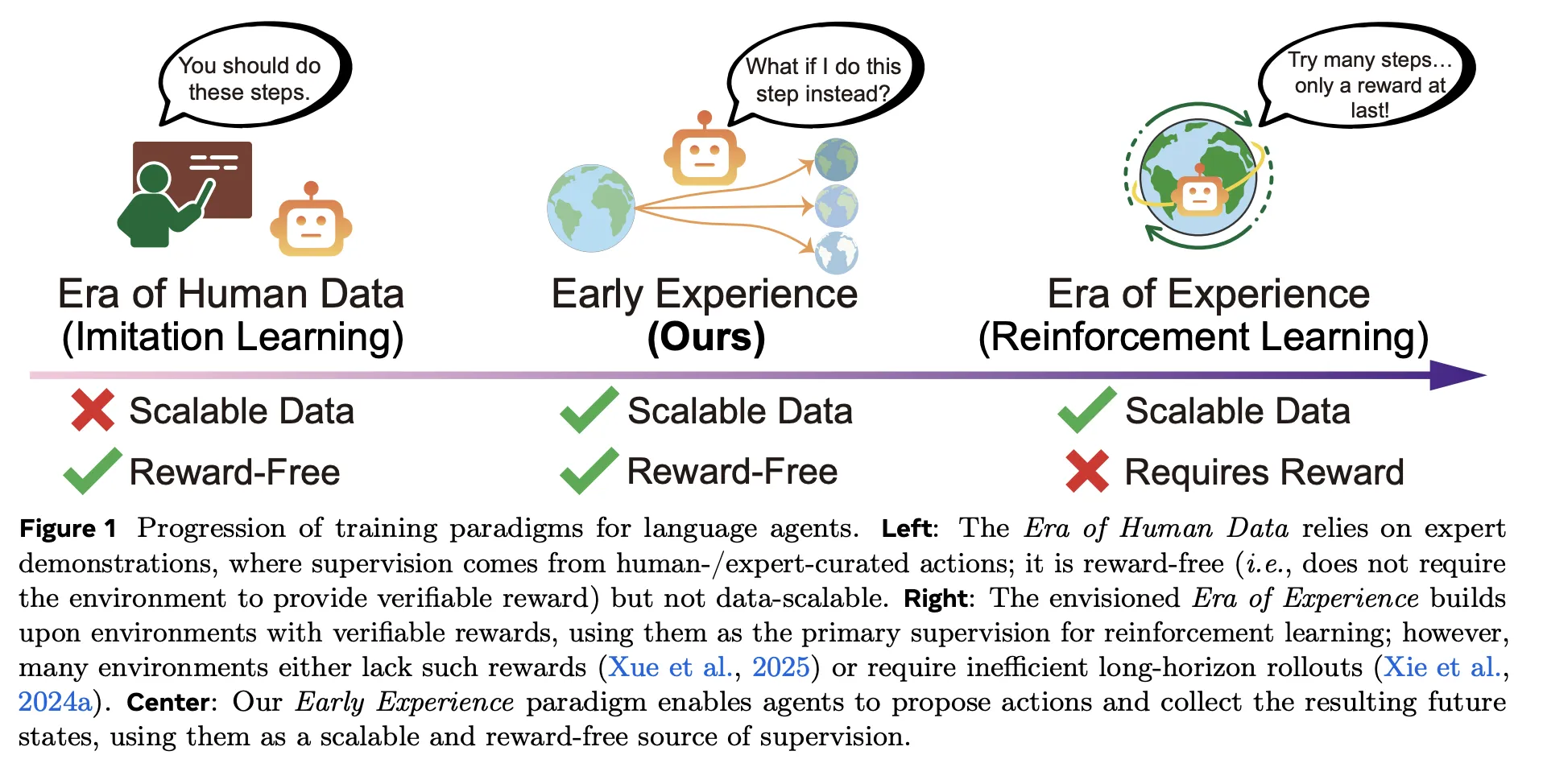
Bridging the Gap: What Early Experience Brings to the Table
Conventional agent training often depends on imitation learning (IL), which mimics expert demonstrations. While IL is computationally efficient, it struggles to generalize beyond the training distribution and requires large amounts of expert data. On the other hand, reinforcement learning (RL) offers the promise of learning from interaction but demands well-defined reward functions and stable training environments-conditions rarely met in complex web or multi-tool scenarios.
Early Experience offers a middle ground: it is reward-free like imitation learning but leverages supervision derived from the agent’s own action outcomes rather than solely expert trajectories. In essence, the agent proposes actions, observes the consequences, and learns directly from these results without any handcrafted reward signals.
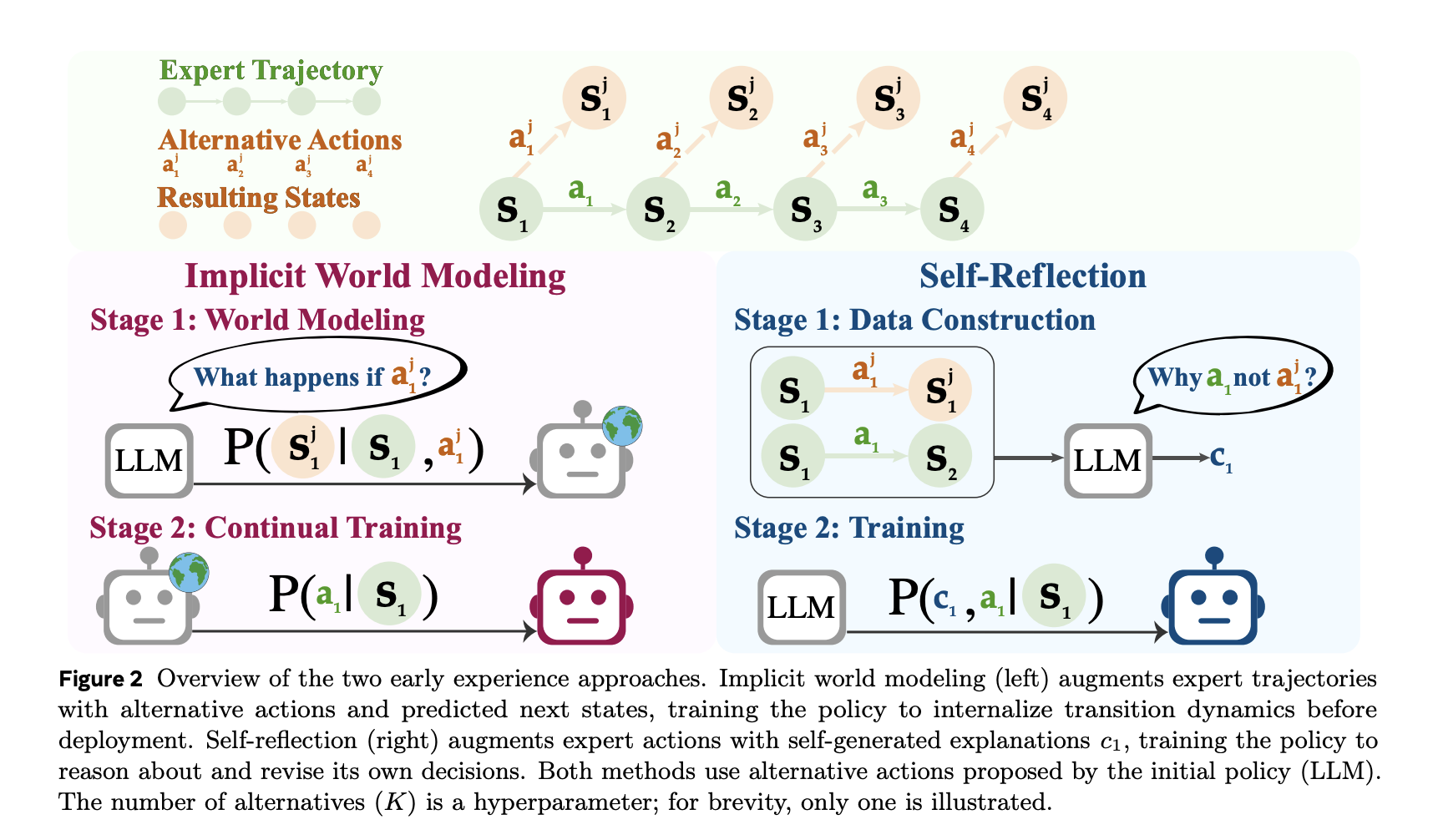
- Implicit World Modeling (IWM): This approach trains the agent to predict the next state based on the current state and chosen action, thereby refining the agent’s internal understanding of environment dynamics and mitigating errors caused by off-policy data.
- Self-Reflection (SR): Here, the agent compares expert actions with alternative choices at the same state, generating grounded explanations for why the expert action leads to better outcomes. This contrastive feedback is then used to fine-tune the policy.
Both methods operate under the same computational budgets and decoding parameters as imitation learning, differing only in the source of training data-agent-generated trajectories instead of additional expert demonstrations.
Comprehensive Benchmarking Across Diverse Tasks
The effectiveness of Early Experience was validated on eight distinct language-agent benchmarks encompassing web navigation, complex planning, scientific reasoning, embodied tasks, and multi-domain API interactions. Notable environments include WebShop (focused on transactional web browsing), TravelPlanner (constraint-based itinerary generation), ScienceWorld, ALFWorld, and Tau-Bench. Across these varied domains, Early Experience demonstrated an average absolute improvement of +9.6% in success rates and +9.4% in out-of-distribution generalization compared to imitation learning.
Moreover, when Early Experience-trained models were used as initializations for reinforcement learning algorithms such as GRPO, they achieved up to +6.4% higher final performance than RL models initialized from imitation learning alone, highlighting its role as a powerful pre-training strategy.
Maximizing Data Efficiency: Achieving More with Less Expert Input
One of the standout advantages of Early Experience is its remarkable efficiency in utilizing expert data. Maintaining a fixed computational budget, this approach matches or outperforms imitation learning while requiring only a fraction of the expert demonstrations. For instance, on the WebShop benchmark, Early Experience surpasses IL performance using just 12.5% (1/8) of the demonstration data. Similarly, on ALFWorld, it reaches parity with IL using only half the expert examples. This suggests that the agent’s self-generated future states provide rich supervisory signals that complement and extend beyond what expert demonstrations alone can offer.
Constructing the Training Dataset: From Expert Seeds to Agent-Driven Exploration
The training pipeline begins with a limited set of expert rollouts to identify representative states within the environment. At these key states, the agent explores alternative actions, executes them, and records the subsequent observations, creating a diverse dataset of state-action-next state triplets.
- For Implicit World Modeling, the dataset consists of (state, action, next state) tuples, with the training objective focused on accurately predicting the next state.
- For Self-Reflection, the data includes the expert action alongside several alternative actions and their observed outcomes. The model then generates a reasoned explanation for why the expert action is superior, which serves as a contrastive learning signal to refine the policy.
Integrating Reinforcement Learning: Complementing Rather Than Replacing
It is important to clarify that Early Experience is not simply “reinforcement learning without rewards.” Instead, it is a supervised learning approach that leverages outcomes experienced by the agent as training labels. In scenarios where reliable reward functions exist, Early Experience can be used as a pre-training phase, followed by conventional reinforcement learning. This sequential training leads to faster convergence and higher performance ceilings, with improvements of up to +6.4% in final success rates compared to RL initialized from imitation learning.
This positions Early Experience as a crucial intermediary step, enabling reward-free pre-training grounded in actual consequences, which can then be enhanced by reward-based RL when applicable.
Summary of Core Insights
- Early Experience introduces a novel reward-free training paradigm using agent-generated future states as supervision, outperforming imitation learning across eight diverse environments.
- Significant absolute performance gains over IL include +18.4% on WebShop, +15.0% on TravelPlanner, and +13.3% on ScienceWorld under equivalent training conditions.
- Demonstration efficiency is markedly improved, achieving superior results with as little as 12.5% of expert data on some benchmarks.
- When used to initialize reinforcement learning, Early Experience boosts final performance by up to +6.4% compared to RL starting from imitation learning.
- Validated across multiple model architectures ranging from 3 billion to 8 billion parameters, showing consistent improvements both in-domain and out-of-domain.
Final Thoughts
Early Experience represents a practical advancement in agent training by replacing fragile rationale-based augmentations with scalable, outcome-grounded supervision that agents can autonomously generate. The dual strategies of Implicit World Modeling and Self-Reflection directly address challenges like off-policy drift and error accumulation over long horizons, explaining their robust gains over imitation learning and enhanced reinforcement learning performance. In complex environments where reward signals are sparse or unreliable-such as web navigation and multi-tool interactions-Early Experience offers a viable, immediately deployable solution that bridges the gap between imitation learning and reinforcement learning.

{kind=link}