
A Team of researchers from USC, Salesforce AI and University of Washington have introduced CoAct-1, a pioneering multi-agent computer-using agent (CUA) that marks a significant leap in autonomous computer operation. By elevating coding to a first-class action—on par with traditional GUI manipulation—CoAct-1 overcomes longstanding challenges of efficiency and reliability in complex, long-horizon computer tasks. On the demanding OSWorld benchmark, CoAct-1 sets a new gold standard, achieving a state-of-the-art (SOTA) success rate of 60.76%, making it the first CUA agent to surpass the 60% mark.
Why CoAct-1? Bridging the Efficiency Gap in Computer-Using Agents
Conventional CUA agents rely solely on pixel-based GUI interaction—emulating human users by clicking, typing, and navigating interfaces. While this approach mimics user workflows, it proves fragile and inefficient for intricate, multi-step tasks, especially those involving dense UI layouts, multi-app pipelines, or complex OS operations. Single errors such as a mis-click can derail entire workflows, and sequence lengths balloon as tasks increase in complexity.
Efforts to mitigate these issues have included augmenting GUI agents with high-level planners, as seen in systems like GTA-1 and modular multi-agent frameworks. However, these methods cannot escape the bottleneck of GUI-centric action spaces, ultimately limiting both efficiency and robustness.
CoAct-1: Hybrid Architecture with Coding as Action
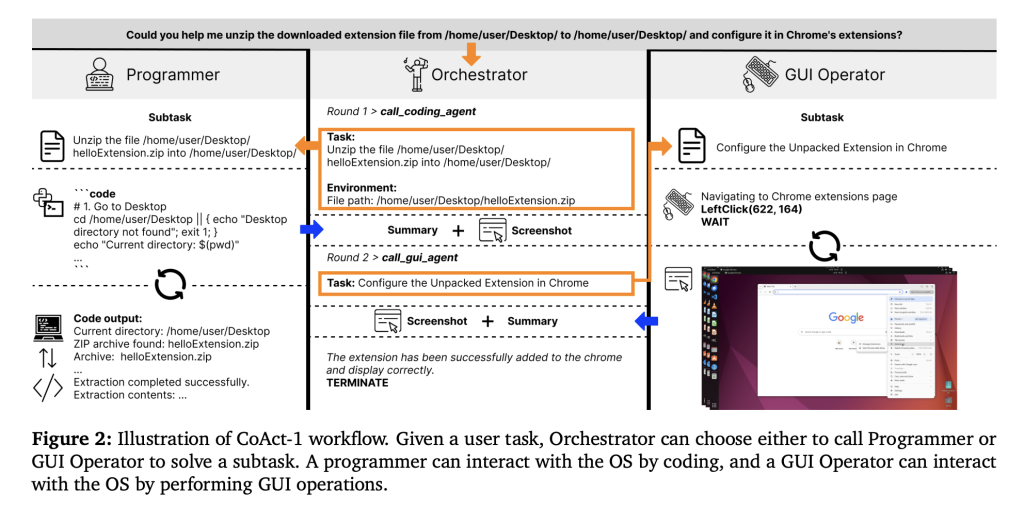
CoAct-1 takes a fundamentally different approach by integrating three specialized agents:
- Orchestrator: The high-level planner that decomposes complex tasks and dynamically delegates each subtask either to the Programmer or the GUI Operator based on task requirements.
- Programmer: Executes backend operations—file management, data processing, environment configuration—directly via Python or Bash scripts, bypassing cumbersome GUI action sequences.
- GUI Operator: Uses a vision-language model to interact with visual interfaces when human-like UI navigation is indispensable.
This hybrid model enables CoAct-1 to strategically substitute brittle and lengthy mouse-keyboard operations with concise, reliable code execution, while still leveraging GUI interactions where necessary.
Evaluation on OSWorld: Record-Setting Performance
OSWorld—a leading benchmark featuring 369 tasks spanning office productivity, IDEs, browsers, file managers, and multi-app workflows—proves an exacting testbed for agentic systems. Each task mirrors real-world language goals and is assessed by a granular rule-based scoring system.
Results
- Overall SOTA Success Rate: CoAct-1 achieves 60.76% on the 100+ step category—the first CUA agent to cross the 60-point threshold. This outpaces GTA-1 (53.10%), OpenAI CUA 4o (31.40%), UI-TARS-1.5 (29.60%), and other leading frameworks.
- Stepped Allowance Performance: At a 100-step budget, CoAct-1 scores 59.93%, again leading all competitors.
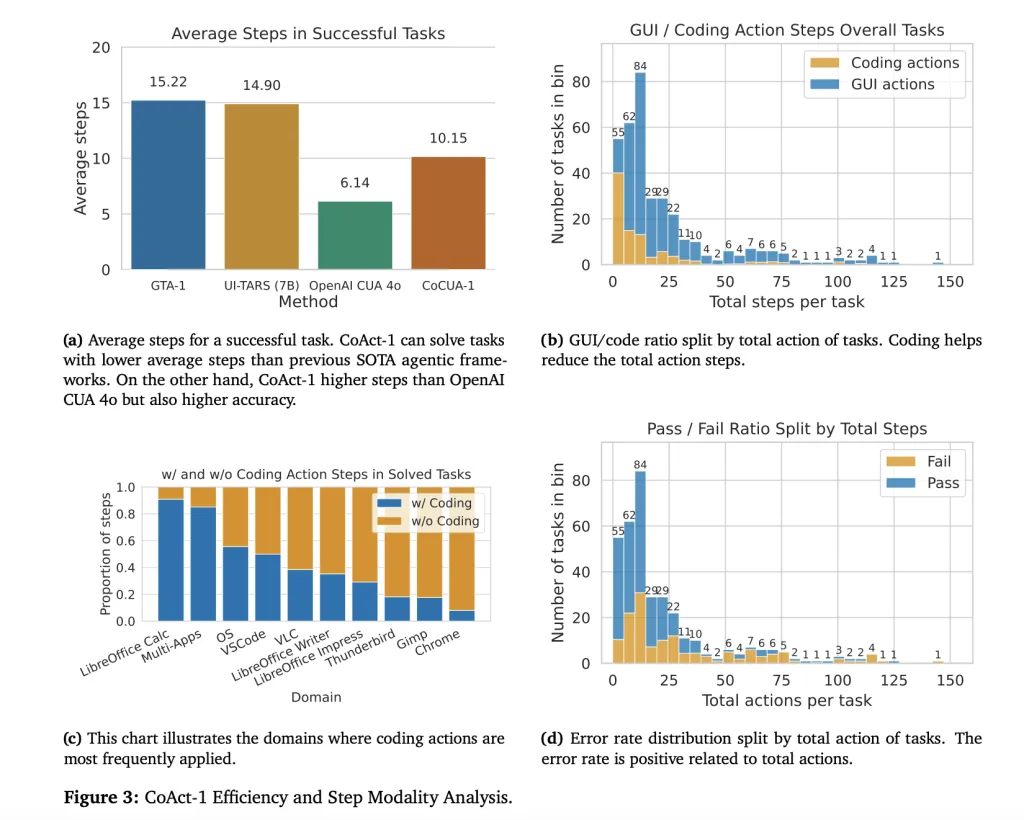
- Efficiency: Completes tasks with an average of 10.15 steps per successful task, compared to 15.22 for GTA-1, 14.90 for UI-TARS, and with much higher success than OpenAI CUA 4o, which, despite fewer steps (6.14), achieves only 31.40% success.
Breakdown
CoAct-1 dominates across task types, with especially large gains in workflows benefitting from code execution:
- Multi-App: 47.88% (vs. GTA-1’s 38.34%)
- OS Tasks: 75.00%
- VLC: 66.07%
- In productivity and IDE domains (LibreOffice Calc, Writer, VSCode), it consistently leads or ties with the SOTA.
Key Insights: What Drives CoAct-1’s Gains?
- Coding Actions Replace Redundant GUI Sequences: For operations like batch image resizing or advanced file manipulations, single scripts replace dozens of error-prone clicks, reducing both steps and risk of failure.
- Dynamic Delegation: The Orchestrator’s flexible task assignment ensures optimal use of coding vs. GUI actions.
- Improvement with Stronger Backbones: The best configuration uses OpenAI CUA 4o for the GUI Operator, OpenAI o3 for the Orchestrator, and o4-mini for the Programmer, reaching the top 60.76% score. Systems using only smaller or less capable backbones score significantly lower.
- Efficiency Correlates with Reliability: Fewer steps directly reduce opportunities for error—the single strongest predictor of successful completion.
Conclusion: A Leap Forward in Generalized Computer Automation
By making coding a first-class system action alongside GUI manipulation, CoAct-1 delivers both a quantum leap in success and efficiency, and illustrates the practical path forward for scalable, reliable autonomous computer agents. Its hybrid architecture and dynamic execution logic set a new high-water mark for the CUA field, heralding robust advances in real-world computer automation.
Check out the and . Feel free to check out our . Also, feel free to follow us on and don’t forget to join our and Subscribe to .

{kind=link}