
Imagine boosting Gemini-2.5 Pro’s performance on the HLE benchmark to 34.1% by integrating 12 to 15 diverse tool-using agents that collaborate and halt early-rather than relying on repeated sampling of a single agent. This innovative concept is realized by Google Cloud AI Research in partnership with MIT, Harvard, and Google DeepMind through TUMIX (Tool-Use Mixture). TUMIX is a dynamic test-time framework that combines a variety of agent types-including text-only, code-executing, web-search-enabled, and guided models-allowing them to exchange intermediate solutions across several refinement cycles and terminate early based on an LLM-powered adjudicator. This approach achieves superior accuracy with reduced computational expense on challenging reasoning datasets such as HLE, GPQA-Diamond, and AIME (2024/2025).
Innovations Behind TUMIX: A Fresh Perspective
- Diverse Modalities Over Mere Quantity: Unlike traditional methods that increase sample counts, TUMIX orchestrates approximately 15 distinct agent styles. These include Chain-of-Thought (CoT) reasoning, code execution, web search, dual-tool agents, and guided variants. Each iteration, agents receive both the original query and the refined answers from their peers, enabling a collaborative message-passing mechanism that enhances early accuracy while gradually converging diversity-making early stopping crucial.
- Smart Early Stopping via LLM Judge: An LLM-based evaluator monitors the consensus among agents and halts the refinement process once a strong agreement is detected, after a minimum number of rounds. This strategy maintains accuracy while cutting inference costs to roughly 49% compared to fixed-round approaches, with token usage dropping to about 46% due to heavier token consumption in later rounds.
- Self-Generated Agent Variants: Beyond manually designed agents, TUMIX leverages the base LLM to autonomously create new agent types. Incorporating these auto-generated agents alongside human-crafted ones yields an additional average accuracy boost of approximately 1.2% without increasing computational overhead. Empirical evidence suggests an optimal ensemble size of around 12 to 15 agent styles.
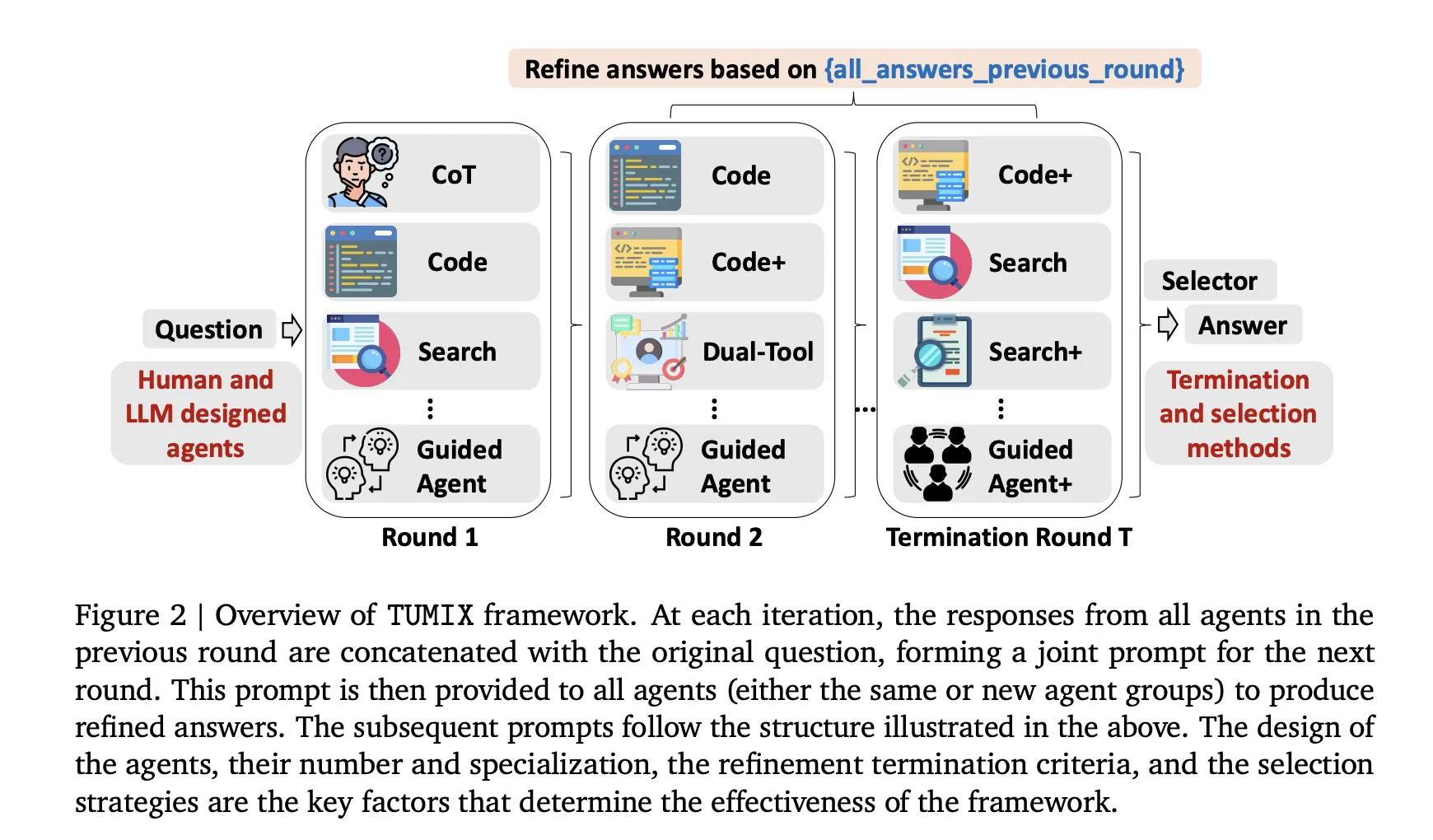
Mechanics of the TUMIX Framework
TUMIX operates by running a heterogeneous ensemble of agents in parallel, including text-based Chain-of-Thought reasoners, code-executing models, web-search-enabled agents, and guided variants. These agents engage in a limited number of refinement rounds, where each agent updates its response based on the original question and the prior answers from other agents-effectively sharing structured notes. After each iteration, an LLM-driven judge assesses the level of agreement and consistency among the agents. If consensus is insufficient, the process continues; otherwise, it stops early, and the final answer is determined through straightforward aggregation methods such as majority voting or selector mechanisms. This multi-tool approach replaces brute-force resampling with diverse reasoning trajectories, enhancing the likelihood of correct answers while managing token and tool usage efficiently. The benefits plateau around 12 to 15 agent styles, with early stopping preserving answer diversity and reducing costs without compromising accuracy.
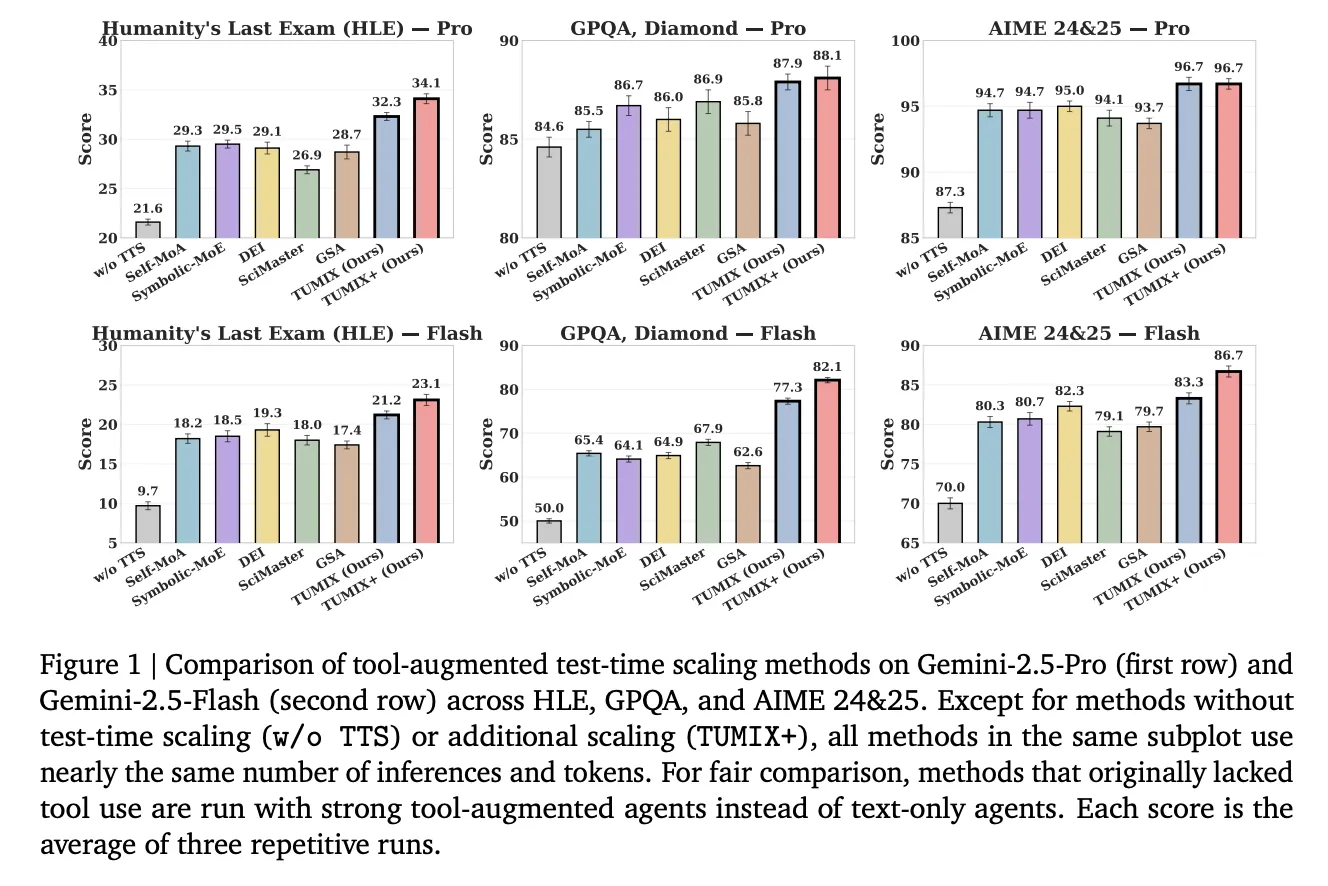
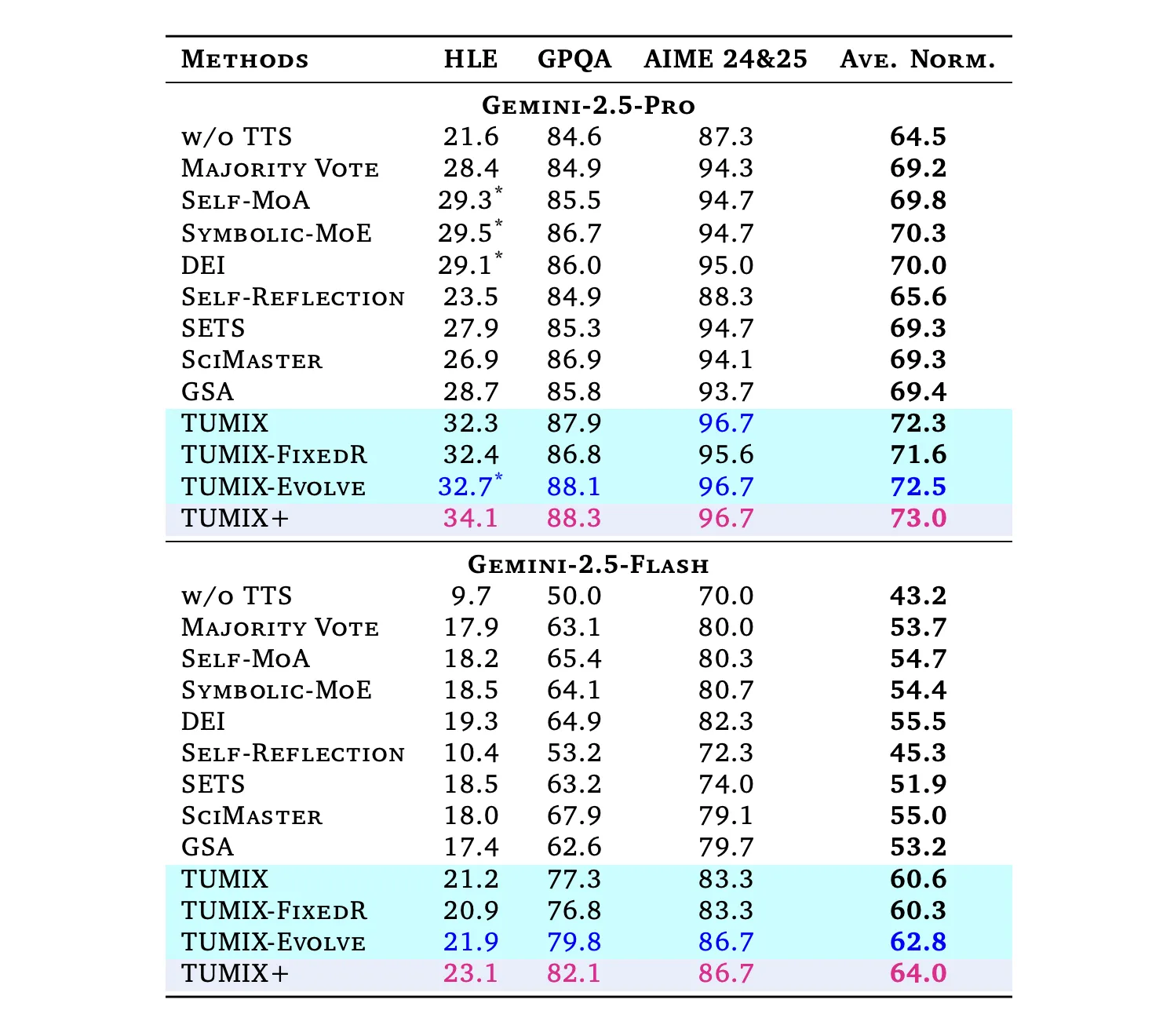
Performance Highlights and Benchmark Outcomes
When compared to leading tool-augmented baselines like Self-MoA, Symbolic-MoE, DEI, SciMaster, and GSA under similar computational budgets, TUMIX consistently delivers superior average accuracy. An enhanced version, TUMIX+, further elevates performance by leveraging additional compute resources:
- HLE (Humanity’s Last Exam): Gemini-2.5 Pro’s accuracy surges from 21.6% to 34.1% with TUMIX+; the Flash variant improves from 9.7% to 23.1%. (HLE is a comprehensive 2,500-question multi-domain benchmark finalized in 2025.)
- GPQA-Diamond: Pro agents achieve up to 88.3% accuracy, while Flash agents reach 82.1%. (GPQA-Diamond represents the most challenging 198-question subset curated by domain experts.)
- AIME 2024/25: Pro agents attain 96.7%, and Flash agents 86.7% accuracy using TUMIX(+) at test time.
Overall, TUMIX outperforms the best prior tool-augmented test-time scaling baselines by an average of +3.55% at comparable costs, and shows gains of +7.8% and +17.4% over no-scaling baselines for Pro and Flash models, respectively.
Insights and Implications
TUMIX represents a significant advancement by reframing test-time scaling as a strategic search across diverse tool-using policies rather than relying on repetitive sampling. The parallel ensemble of text, code, and search agents broadens the solution space, while the LLM-based judge’s early stopping mechanism preserves answer diversity and curtails token and tool consumption-critical for latency-sensitive applications. The notable improvement on the HLE benchmark (34.1% with Gemini-2.5 Pro) aligns with the benchmark’s extensive 2,500-question design, and the identified optimal ensemble size of 12 to 15 agent styles suggests that careful agent selection, rather than sheer quantity, is key to maximizing performance.

{kind=link}