
What Lies Beyond Transformers? Google Research has introduced innovative approaches named Titans and MIRAS to equip sequence models with effective long-term memory capabilities, all while preserving parallel training efficiency and near-linear inference speed.
Titans represents a specific architecture that integrates a deep neural memory module into a Transformer-like framework. Meanwhile, MIRAS offers a broad conceptual framework that interprets many contemporary sequence models as forms of online optimization operating over associative memory.
Rethinking Memory in Sequence Models: The Need for Titans and MIRAS
Traditional Transformer models rely on attention mechanisms over a key-value cache, enabling powerful in-context learning. However, their computational cost scales quadratically with the length of the input sequence, limiting practical context sizes despite optimizations like FlashAttention and kernel-based methods.
On the other hand, efficient linear recurrent neural networks and state space models-such as Mamba-2-compress historical information into a fixed-size state, resulting in linear computational complexity relative to sequence length. Yet, this compression inevitably sacrifices detail, impairing performance on tasks requiring extremely long context understanding, such as genomic sequence analysis or extensive document retrieval.
Titans and MIRAS bridge these paradigms by combining precise short-term memory via attention on recent tokens with a dedicated neural module that serves as long-term memory. This module learns dynamically during inference and is architected for parallelizable operations on modern accelerators.
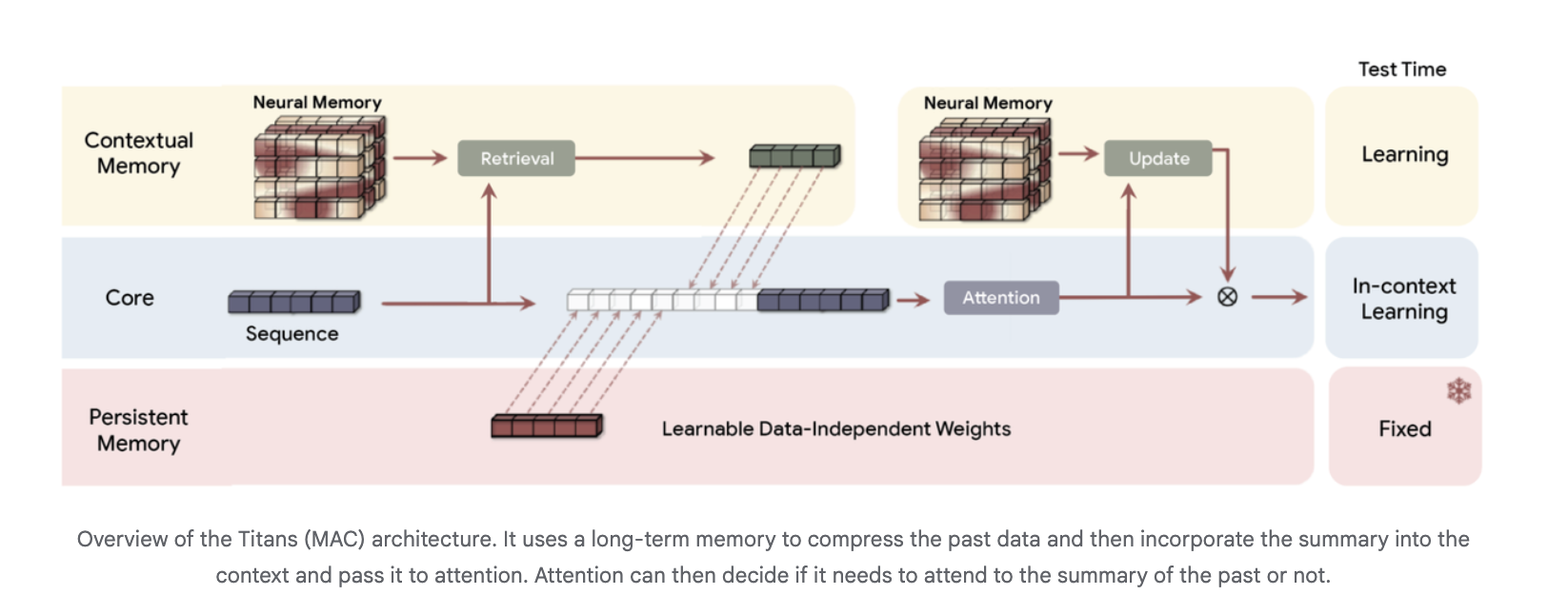
Titans: A Neural Long-Term Memory System That Adapts During Inference
Titans introduces a neural long-term memory component structured as a deep multilayer perceptron (MLP), diverging from traditional vector or matrix-based memory states. In this design, attention mechanisms function as short-term memory, focusing on a limited token window, while the neural memory module persistently retains information over extended sequences.
For each token processed, Titans defines an associative memory loss function:
L(M; k, v) = ‖M(k) − v‖²
Here, M represents the current memory state, k the key, and v the value. The gradient of this loss with respect to memory parameters acts as a “surprise metric”: large gradients indicate unexpected tokens warranting storage, whereas small gradients correspond to predictable tokens that can be deprioritized.
Memory parameters are updated during inference using gradient descent enhanced with momentum and weight decay, mechanisms that respectively facilitate retention and controlled forgetting. To maintain computational efficiency, updates are computed via batched matrix multiplications over sequence chunks, enabling parallel training across long sequences.
The Titans architecture typically employs three distinct memory branches, especially in the Titans MAC variant:
- Core branch: Executes standard in-context learning through attention.
- Contextual memory branch: Learns from recent sequence data.
- Persistent memory branch: Contains fixed weights encoding pretrained knowledge.
The long-term memory condenses historical tokens into a compact summary, which is then fed as additional context into the attention mechanism. This allows attention to selectively access the summarized long-term information.
Performance Highlights of Titans
In benchmarks involving language modeling and commonsense reasoning-such as C4, WikiText, and HellaSwag-Titans consistently surpass state-of-the-art linear recurrent models like Mamba-2 and Gated DeltaNet, as well as Transformer++ variants of similar scale. This superiority is attributed to the enhanced expressive capacity of deep neural memory and its robustness as context length increases. Notably, deeper neural memories with equivalent parameter counts yield lower perplexity scores.
For tasks demanding extreme long-context recall, the BABILong benchmark evaluates the ability to retrieve facts scattered across massive documents. Titans outperforms all competitors, including large-scale models like GPT-4, while utilizing significantly fewer parameters and scaling to context windows exceeding two million tokens.
Despite the added complexity of neural memory, Titans maintains efficient parallel training and near-linear inference speed. While pure neural memory modules are marginally slower than the fastest linear recurrent models, hybrid Titans architectures combining Sliding Window Attention achieve a favorable balance between throughput and accuracy.
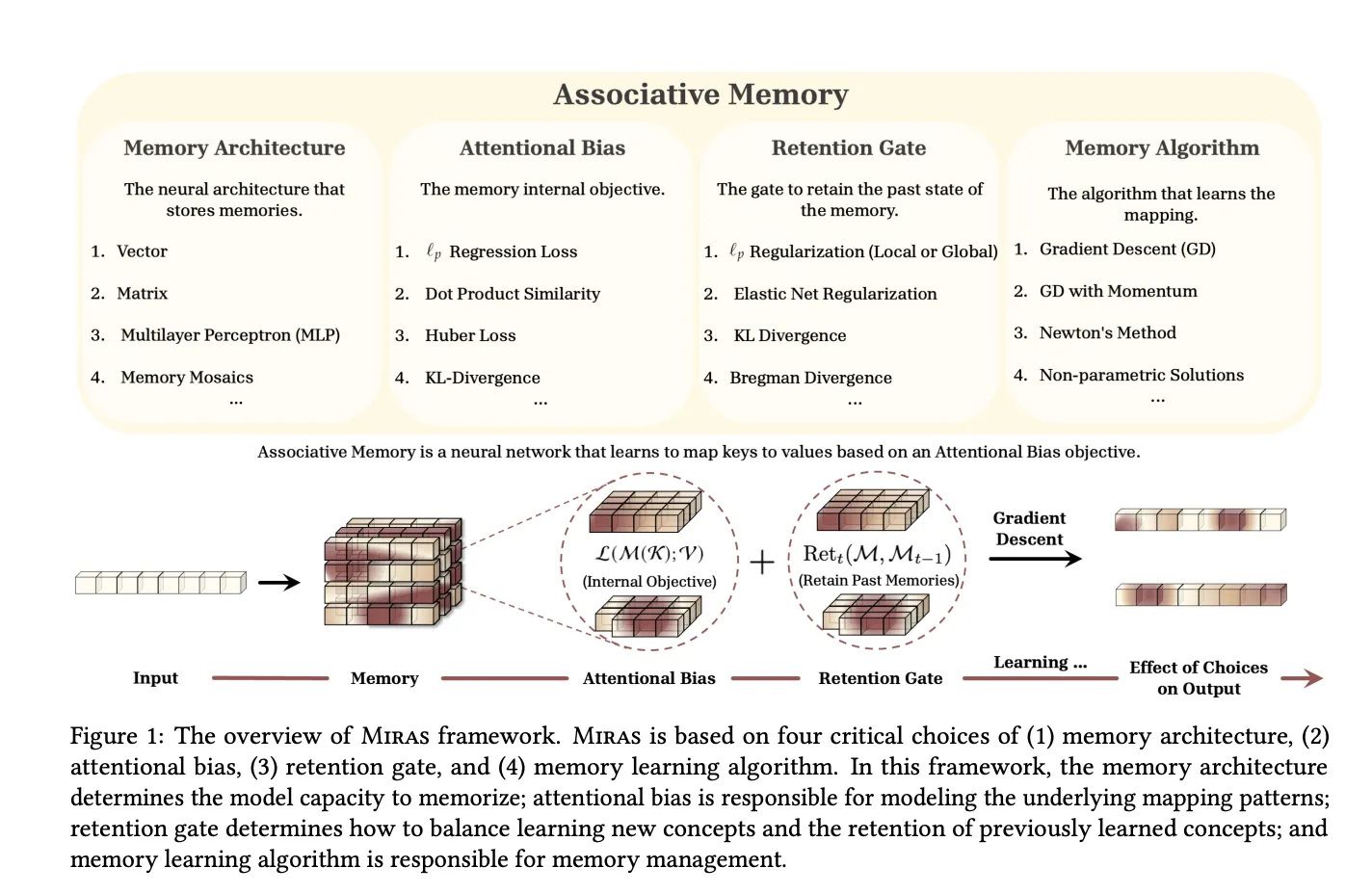
MIRAS: A Comprehensive Framework Viewing Sequence Models as Associative Memories
The MIRAS framework generalizes the concept of sequence models as associative memories that map keys to values while balancing learning new information and forgetting outdated data.
MIRAS characterizes any sequence model through four fundamental components:
- Memory structure: The form of memory representation, such as vectors, linear maps, or multilayer perceptrons.
- Attentional bias: The internal loss function defining the similarity criteria the memory prioritizes.
- Retention gate: A regularization mechanism that maintains memory stability by controlling deviation from past states.
- Memory algorithm: The online optimization strategy, commonly gradient descent with momentum.
Through this lens, MIRAS unifies various model families:
- Hebbian-style linear recurrent models and RetNet, interpreted as dot product-based associative memories.
- Delta rule-based models like DeltaNet and Gated DeltaNet, which use mean squared error (MSE) losses with value replacement and specific retention gates.
- Titans’ neural long-term memory, a nonlinear MSE-based memory optimized via gradient descent with momentum and featuring both local and global retention.
Importantly, MIRAS extends beyond conventional MSE or dot product objectives by introducing novel attentional biases based on L∞ norms, robust Huber loss, and robust optimization techniques. It also explores new retention gates inspired by probability simplex divergences, elastic net regularization, and Bregman divergence.
From this expanded design space, MIRAS proposes three attention-free architectures:
- Moneta: Employs a two-layer MLP memory with L∞ attentional bias and a hybrid retention gate grounded in generalized norms.
- Yaad: Utilizes the same MLP memory but with Huber loss attentional bias and a forget gate conceptually related to Titans.
- Memora: Implements regression loss as attentional bias and a KL divergence-based retention gate over a probability simplex memory.
These MIRAS variants replace traditional attention blocks within a LLaMA-style backbone, incorporate depthwise separable convolutions in the MIRAS layer, and can be combined with Sliding Window Attention in hybrid configurations. Training remains parallelizable by segmenting sequences into chunks and computing gradients relative to the memory state from preceding chunks.
Experimental results demonstrate that Moneta, Yaad, and Memora match or exceed the performance of strong linear recurrent models and Transformer++ architectures on language modeling, commonsense reasoning, and tasks requiring intensive recall, all while maintaining linear-time inference.
Summary of Key Insights
- Titans introduces a deep neural long-term memory module that adapts during inference, leveraging gradient descent on an L2 associative memory loss to selectively store surprising tokens, with updates optimized for parallel execution on accelerators.
- By integrating attention with neural memory, Titans effectively manages long contexts, utilizing multiple memory branches-core, contextual, and persistent-to balance short-range precision and long-range information retention beyond two million tokens.
- Titans outperforms leading linear RNNs and Transformer++ baselines, including Mamba-2 and Gated DeltaNet, on language modeling and reasoning benchmarks at comparable parameter scales, while maintaining competitive throughput.
- On extreme long-context recall challenges like BABILong, Titans achieves superior accuracy compared to all baselines, including larger attention-based models such as GPT-4, with fewer parameters and efficient training and inference.
- MIRAS offers a unified theoretical framework for sequence models as associative memories, defined by memory structure, attentional bias, retention gate, and optimization rule, enabling novel attention-free architectures like Moneta, Yaad, and Memora that rival or surpass linear RNNs and Transformer++ on long-context and reasoning tasks.

{kind=link}