 While Maintaining Benchmark Parity")
Contents Overview
DeepSeek has introduced DeepSeek-V3.2-Exp, an incremental enhancement over V3.1, featuring the novel DeepSeek Sparse Attention (DSA) mechanism. This trainable sparsification technique is designed to optimize performance for extended context lengths. Alongside this, DeepSeek has slashed API pricing by over 50%, reflecting the efficiency improvements achieved.
Innovative Two-Phase Attention Architecture
The V3.2-Exp update retains the foundational V3/V3.1 architecture, which combines Mixture of Experts (MoE) and Multi-Head Latent Attention (MLA). It integrates a novel two-step attention process:
- A streamlined “indexer” module that evaluates and scores tokens within the context.
- A sparse attention mechanism that focuses computation on a selected subset of tokens.
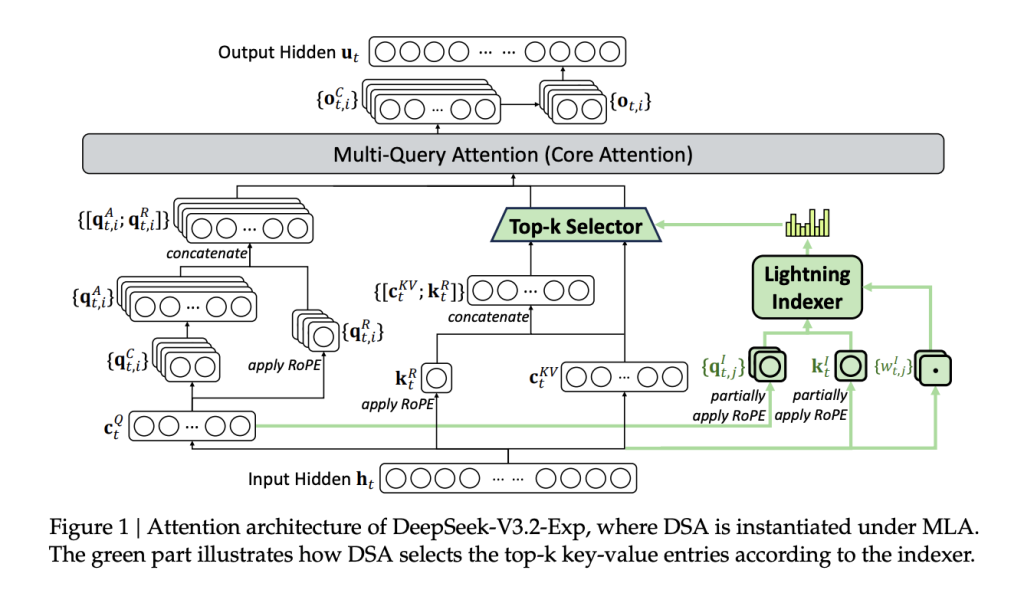
DeepSeek Sparse Attention: Mechanism and Training
The core innovation, DeepSeek Sparse Attention (DSA), divides the attention computation into two distinct layers:
1. Lightweight Indexing with FP8 Precision
For each query token, a compact scoring function operates in FP8 precision using a limited number of attention heads. This “indexer” rapidly computes logits that estimate the relevance of preceding tokens. Employing ReLU activations, this stage is computationally inexpensive, significantly reducing latency and FLOPs compared to traditional dense attention.
2. Top-k Token Selection and Sparse Attention
Following indexing, the system selects the top-k (typically 2048) key-value pairs per query token. Attention is then computed exclusively over this subset, reducing the complexity from O(L²) to approximately O(L × k), where k << L. This approach maintains the ability to attend to distant tokens when necessary, preserving model expressiveness.
Training Strategy: The indexer is trained to mimic the dense attention distribution by minimizing the Kullback-Leibler divergence between its output and the full attention heads’ summed distribution. Training begins with a “dense warm-up” phase (~2.1 billion tokens) where the main model is frozen, followed by a sparse training phase (~943.7 billion tokens) with a learning rate around 7.3e-6. During sparse training, gradients for the indexer are kept separate from the main language model loss to stabilize learning.
Implementation Details: DSA is integrated within the MLA framework, operating in Multi-Query Attention (MQA) mode during decoding. This design allows latent key-value entries to be shared across query heads, optimizing kernel-level reuse and throughput.
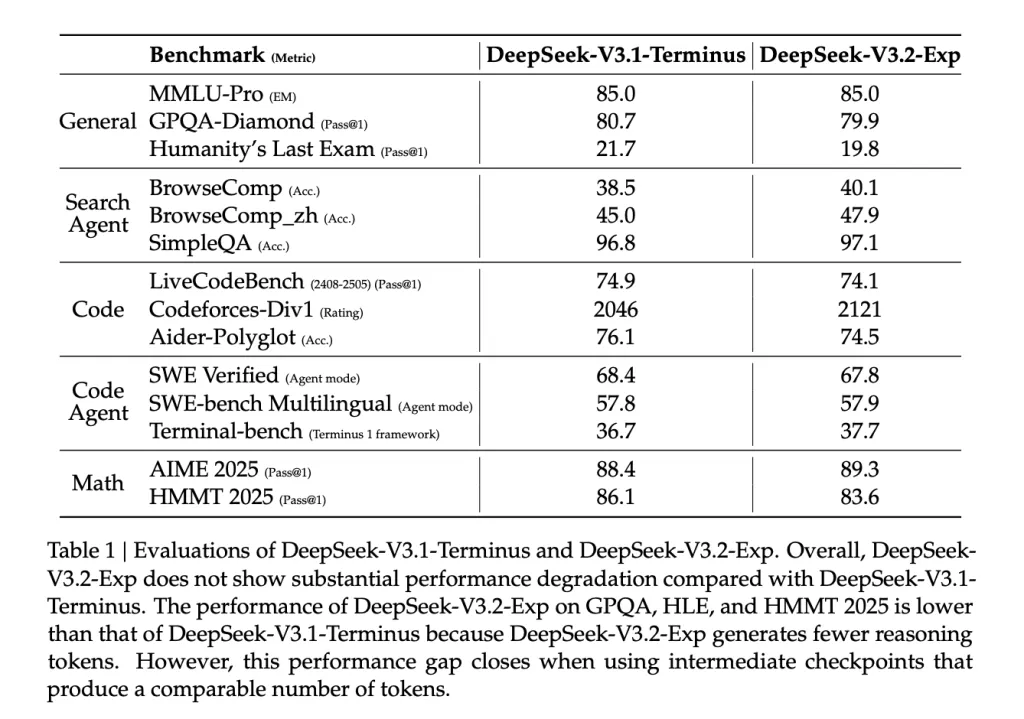
Evaluating Efficiency and Performance
- Cost Efficiency at Extreme Context Lengths (128k tokens): DeepSeek provides detailed cost analyses for both prefill and decode phases on H800 GPU clusters (priced at approximately $2 per GPU-hour). The DSA mechanism notably reduces decoding costs, with reported savings up to sixfold at 128k tokens. Prefill costs also decrease due to optimized masked multi-head attention simulations at shorter sequence lengths. While these figures are promising, independent validation is awaited to confirm the 83% cost reduction widely discussed in community forums.
- Maintaining Benchmark Performance: Benchmark results indicate that DeepSeek V3.2-Exp sustains parity with previous versions, achieving an MMLU-Pro score of 85.0. Minor fluctuations in tasks like GPQA, HLE, and HMMT are attributed to fewer reasoning tokens processed, while agentic and search-related benchmarks (e.g., BrowseComp) show slight improvements. These differences tend to diminish when comparing models at equivalent token throughput checkpoints.
- Production-Ready Features: Immediate support for DSA in frameworks such as SGLang and vLLM highlights the practical deployment focus of this update. The project also leverages open-source components like TileLang, DeepGEMM (for indexer logits), and FlashMLA (for sparse kernel execution), underscoring a commitment to accessible, high-performance tooling.
- API Pricing Impact: Reflecting the efficiency gains, DeepSeek has reduced API costs by more than half, aligning with public statements and media coverage emphasizing the goal of making long-context inference more affordable.
Concluding Insights
DeepSeek V3.2-Exp demonstrates that trainable sparsity through DSA can significantly enhance long-context processing efficiency without sacrificing accuracy. The official documentation confirms over 50% reductions in API pricing, with immediate runtime support available. Early community reports suggest even greater decoding speedups at 128k token lengths, though these require further independent benchmarking under consistent batching and caching conditions.
For practitioners, the key recommendation is to consider V3.2-Exp as a straightforward upgrade candidate for retrieval-augmented generation (RAG) and long-document workflows, where quadratic attention costs dominate. Rigorous end-to-end testing on your infrastructure is advised to validate throughput and output quality improvements.
Frequently Asked Questions
1) What distinguishes DeepSeek V3.2-Exp from earlier versions?
V3.2-Exp is an experimental, intermediate release building upon V3.1-Terminus, introducing DeepSeek Sparse Attention (DSA) to enhance efficiency for extended context lengths.
2) Is DeepSeek V3.2-Exp fully open source, and what license governs it?
Yes, the codebase and model weights are openly available under the permissive MIT license, as specified in the official model documentation.
3) How does DeepSeek Sparse Attention (DSA) function in practice?
DSA incorporates a lightweight indexing step that scores and selects a subset of relevant tokens, followed by focused attention computation on this subset. This “fine-grained sparse attention” approach delivers substantial efficiency gains during training and inference on long sequences, while maintaining output quality comparable to dense attention models.
Explore the latest advancements in long-context transformer efficiency and consider integrating DeepSeek V3.2-Exp into your AI pipelines to leverage its cost and performance benefits.

{kind=link}