
How can advanced multimodal reasoning for documents, charts, and videos be achieved using only a 3-billion-parameter class model in production environments? Baidu addresses this challenge with the introduction of a new addition to the ERNIE-4.5 open-source lineup: ERNIE-4.5-VL-28B-A3B-Thinking. This vision-language model is specifically engineered to excel in understanding complex visual and textual data while maintaining a minimal active parameter footprint.
Innovative Architecture and Training Methodology
ERNIE-4.5-VL-28B-A3B-Thinking is constructed upon the ERNIE-4.5-VL-28B-A3B Mixture of Experts (MoE) framework, which integrates a heterogeneous multimodal design. This architecture shares parameters between text and vision modalities while incorporating specialized experts tailored to each modality. Although the model encompasses approximately 30 billion parameters in total, it activates only 3 billion parameters per token through an advanced A3B routing mechanism. This approach delivers the computational efficiency and memory usage comparable to a 3-billion-parameter model, yet retains the expansive capacity necessary for sophisticated reasoning tasks.
To enhance its multimodal comprehension, the model undergoes an intermediate training phase on an extensive visual-language reasoning dataset. This stage sharpens its ability to semantically align visual inputs with textual information, a critical factor for interpreting dense document text and intricate chart details. Additionally, ERNIE-4.5-VL-28B-A3B-Thinking employs multimodal reinforcement learning techniques, including GSPO and IcePop strategies, combined with dynamic difficulty sampling. These methods stabilize the MoE training process and encourage the model to tackle more challenging examples effectively.
Core Functionalities and Use Cases
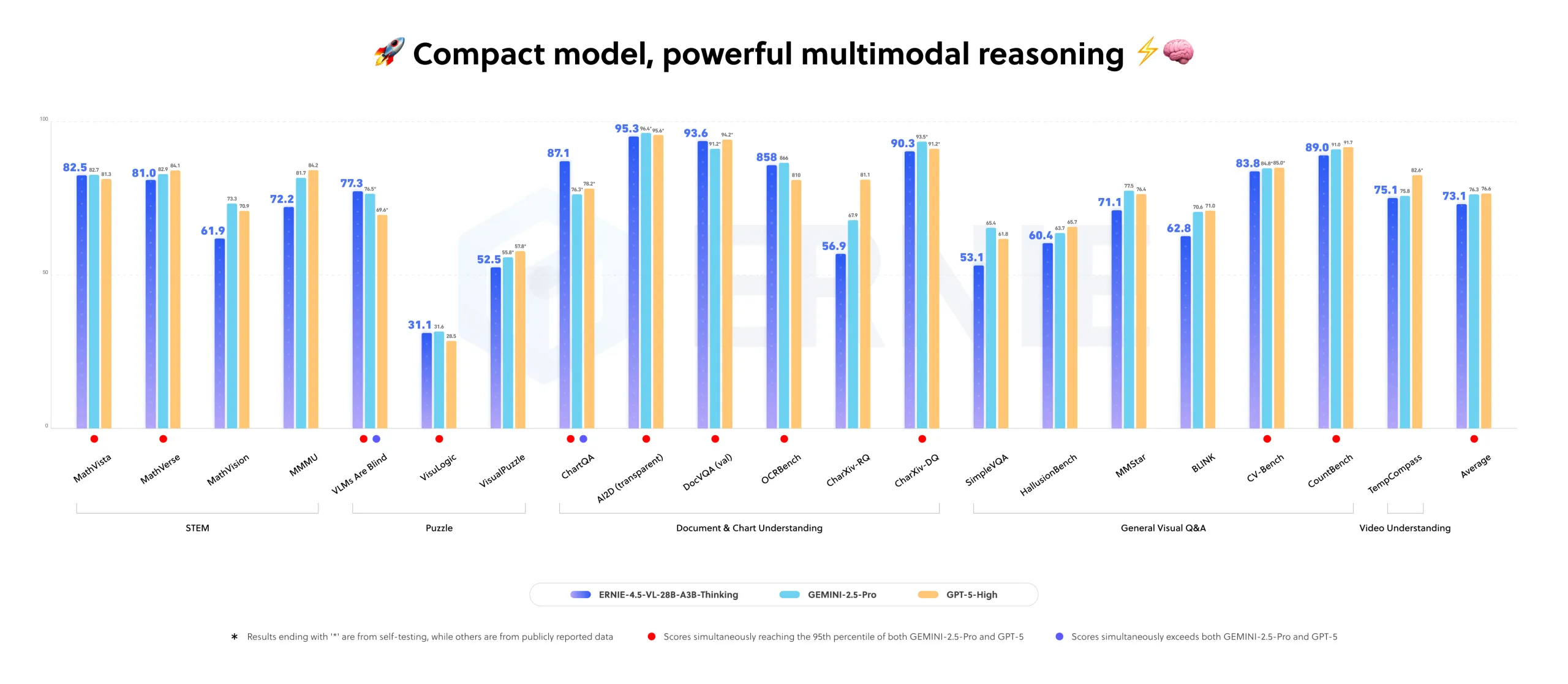
Baidu positions this model as a compact yet powerful multimodal reasoning engine capable of activating only 3 billion parameters while delivering performance close to larger flagship models on internal evaluations. Its key features encompass visual reasoning, STEM problem-solving, visual grounding, iterative image-based thinking, tool integration, and video comprehension.
At the heart of its capabilities lies the “Thinking with Images” function, which allows the model to focus on specific image regions, analyze cropped segments, and synthesize these localized insights into comprehensive answers. This iterative zoom-and-reason process enhances its understanding of complex visuals. Complementing this, the model supports tool utilization, enabling it to invoke external resources such as image search engines when internal knowledge is insufficient. These functionalities are seamlessly integrated into the model’s reasoning and tool invocation pipelines during deployment.
Benchmark Performance and Market Position
ERNIE-4.5-VL-28B-A3B-Thinking demonstrates competitive or superior results compared to models like Qwen-2.5-VL-7B and Qwen-2.5-VL-32B across a variety of benchmarks, all while maintaining a lower active parameter count. The ERNIE-4.5-VL series supports both “thinking” and “non-thinking” operational modes, with the former enhancing reasoning-intensive tasks without compromising perceptual accuracy.
Specifically, the Thinking variant is reported to rival leading industry models in internal multimodal benchmarks, showcasing its strength in real-world applications involving document analysis, chart interpretation, and video segment localization.
Summary of Key Advantages
- Utilizes a Mixture of Experts architecture with roughly 30 billion total parameters but activates only 3 billion per token, optimizing efficiency for multimodal reasoning.
- Enhanced for document, chart, and video comprehension through a dedicated mid-training phase and multimodal reinforcement learning techniques such as GSPO, IcePop, and dynamic difficulty sampling.
- “Thinking with Images” enables iterative focus on image regions for detailed reasoning, while tool integration allows access to external resources like image search for extended knowledge.
- Excels in analytics chart interpretation, STEM circuit problem-solving, visual grounding with JSON-based bounding boxes, and precise video segment timestamping.
- Released under the Apache License 2.0, the model supports deployment via popular frameworks including Transformers, vLLM, and FastDeploy, and can be fine-tuned using ERNIEKit with methods like SFT, LoRA, and DPO for commercial multimodal applications.
Model Comparison Overview
| Model | Training Phase | Total / Active Parameters | Supported Modalities | Maximum Context Length (tokens) |
|---|---|---|---|---|
| ERNIE-4.5-VL-28B-A3B-Base | Pretraining | 28B total, 3B active per token | Text, Vision | 131,072 |
| ERNIE-4.5-VL-28B-A3B (Posttraining) | Posttraining chat model | 28B total, 3B active per token | Text, Vision | 131,072 |
| ERNIE-4.5-VL-28B-A3B-Thinking | Reasoning-focused mid-training | 28B architecture, 3B active per token, 30B total model size | Text, Vision | 131,072 |
| Qwen2.5-VL-7B-Instruct | Posttraining vision-language model | ~8B total (7B class) | Text, Image, Video | 32,768 |
| Qwen2.5-VL-32B-Instruct | Posttraining plus reinforcement learning | 33B total | Text, Image, Video | 32,768 |
Final Insights
ERNIE-4.5-VL-28B-A3B-Thinking represents a pragmatic solution for organizations seeking advanced multimodal reasoning capabilities on documents, charts, and videos without the overhead of activating massive parameter counts. By combining a Mixture-of-Experts design with innovative training strategies and tool integration, this model delivers a deployable, efficient, and powerful platform tailored for complex analytical and understanding tasks in real-world scenarios.

{kind=link}