
PEVA predicts future video frames from previous frames and specified 3D pose changes, enabling generation of atomic action videos, counterfactual simulations, and extended video sequences.
Challenges in Modeling Embodied Agents
Recent progress in world models has enhanced our ability to forecast future states for planning and control, spanning from intuitive physics to multi-step video prediction. However, most existing models fall short when applied to truly embodied agents-those that physically interact with the real world through complex, high-dimensional actions. Unlike abstract control signals, embodied agents operate with a physically grounded action space and perceive the environment from an egocentric perspective, which introduces unique challenges such as dynamic viewpoints and diverse real-world scenarios.
- Context-Dependent Perception and Action: Identical visual inputs can correspond to different movements, and the same action can appear differently depending on context, reflecting the complexity of goal-driven human behavior.
- High-Dimensional, Structured Control: Human full-body motion involves over 48 degrees of freedom, governed by hierarchical and time-dependent dynamics.
- Egocentric Vision Limits Body Visibility: First-person views reveal intentions but obscure the body itself, requiring models to infer physical actions from indirect visual cues.
- Delayed Perceptual Feedback: Visual information often lags behind actions, necessitating long-term temporal reasoning and prediction.
To build effective world models for embodied agents, it is essential to ground learning in real-world, egocentric data that captures the interplay between perception, intention, and complex body movements, including both locomotion and manipulation.
Introducing PEVA: Predicting Egocentric Video from Whole-Body Actions
We present PEVA, a novel framework designed to forecast egocentric video conditioned on detailed human body motion. PEVA leverages kinematic pose trajectories structured by the body’s joint hierarchy to simulate how physical actions influence the environment from a first-person viewpoint. Trained on Nymeria-a large-scale dataset combining real-world egocentric video with precise body pose capture-PEVA employs an autoregressive conditional diffusion transformer to model the intricate relationship between full-body motion and visual outcomes.
This approach marks a pioneering effort to capture complex embodied behaviors and environmental interactions through human-perspective video prediction, enabling applications such as action-conditioned video synthesis and embodied planning.
Capturing Motion with Structured Action Representations
To effectively link human motion with egocentric vision, PEVA encodes each action as a comprehensive, high-dimensional vector that reflects both global translation and detailed joint rotations. The model represents motion in 3D space, using 3 degrees of freedom for root translation and 15 upper-body joints, each described by Euler angles, resulting in a 48-dimensional action space. Motion capture data is synchronized with video frames and transformed into a pelvis-centered local coordinate system to ensure invariance to position and orientation. Normalization of positions and rotations stabilizes training, while inter-frame motion differences enable the model to learn temporal dynamics connecting physical movement to visual changes.
Architecture: Autoregressive Conditional Diffusion Transformer
Building upon the Conditional Diffusion Transformer (CDiT) framework, originally designed for navigation tasks with simple control inputs, PEVA extends this architecture to handle the complexity of whole-body human motion. Key innovations include:
- Random Timeskips: Training with variable temporal skips allows the model to capture both short-term dynamics and longer activity patterns.
- Sequence-Level Training: Loss functions are applied over prefixes of motion sequences, encouraging coherent predictions across entire action sequences.
- Action Embeddings: High-dimensional action vectors are embedded and concatenated to condition each adaptive layer normalization (AdaLN) layer, enabling nuanced control over the generation process.
Inference and Rollout Mechanism
During inference, PEVA generates future video frames by conditioning on a set of past context frames encoded into latent representations. The model progressively denoises noisy latent frames using the diffusion process. To optimize efficiency, attention mechanisms are restricted: self-attention is applied only within the target frame, and cross-attention is limited to the last context frame. For action-conditioned predictions, an autoregressive rollout strategy is employed-each predicted frame is appended to the context, and the oldest frame is dropped as the sequence advances. The final latent outputs are decoded back into pixel space using a variational autoencoder (VAE) decoder.
Decomposing Movements into Atomic Actions
To evaluate PEVA’s understanding of fine-grained motion effects, complex human movements are broken down into atomic actions, such as directional hand movements and whole-body rotations or translations. This decomposition allows the model to demonstrate precise control over egocentric video generation in response to specific joint-level commands.
Examples of Body Movement Actions
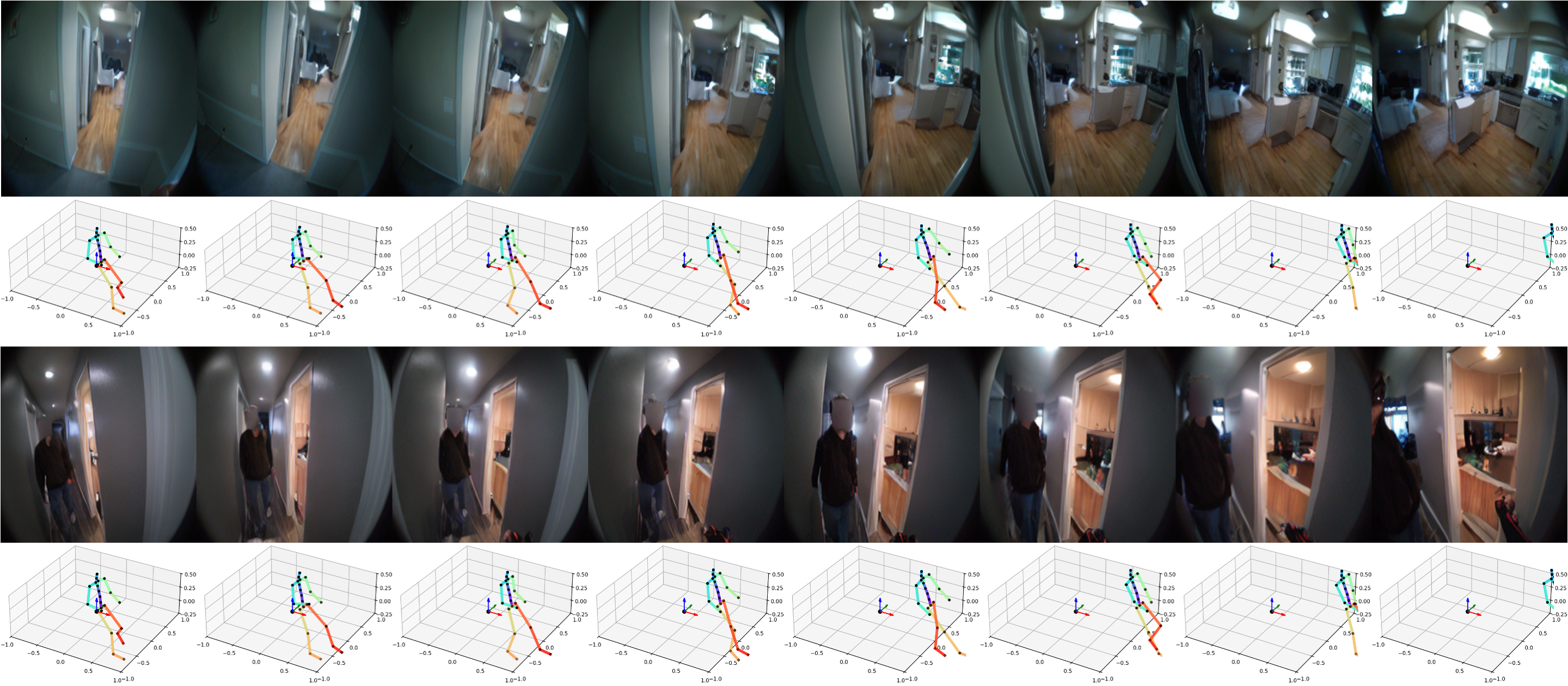 Move Forward
Move Forward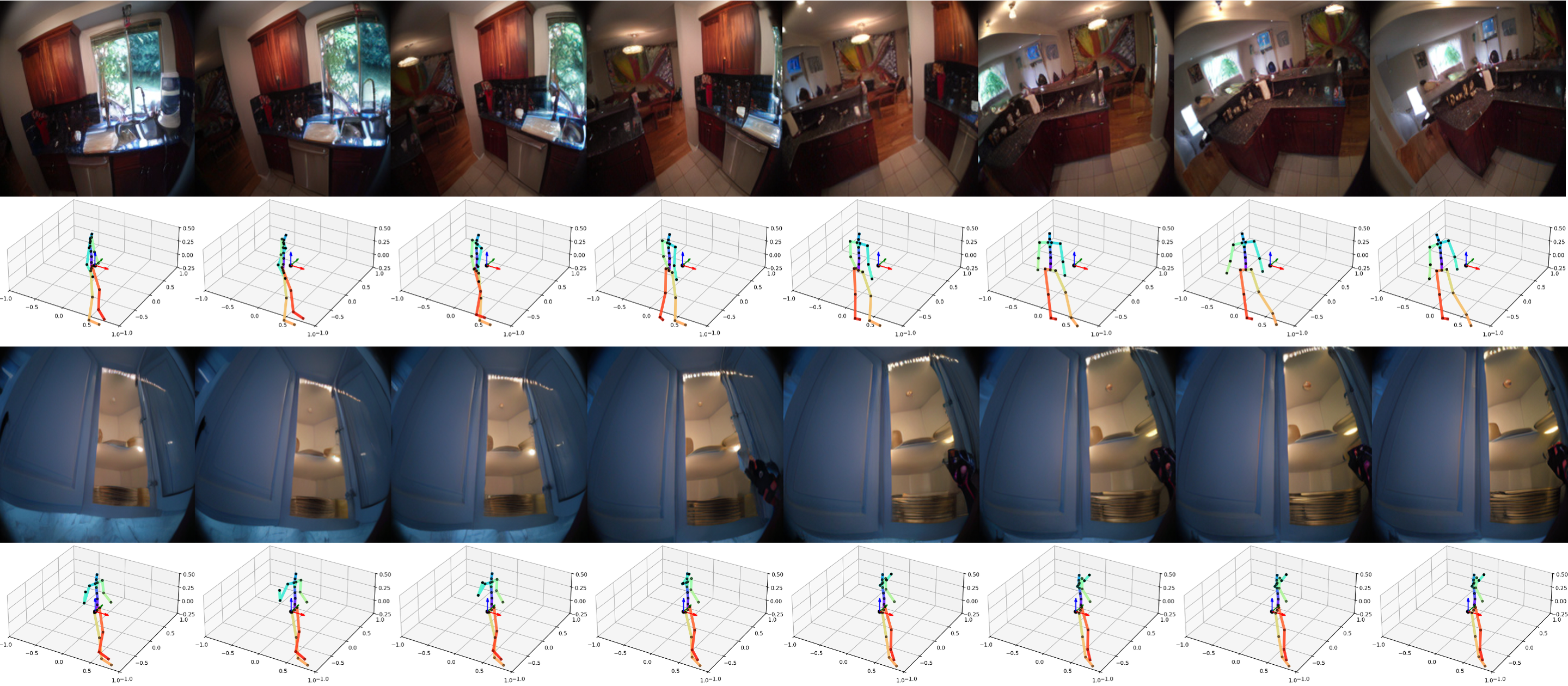 Rotate Left
Rotate Left Rotate Right
Rotate RightLeft Hand Movements
 Move Left Hand Up
Move Left Hand Up Move Left Hand Down
Move Left Hand Down Move Left Hand Left
Move Left Hand Left Move Left Hand Right
Move Left Hand RightRight Hand Movements
 Move Right Hand Up
Move Right Hand Up Move Right Hand Down
Move Right Hand Down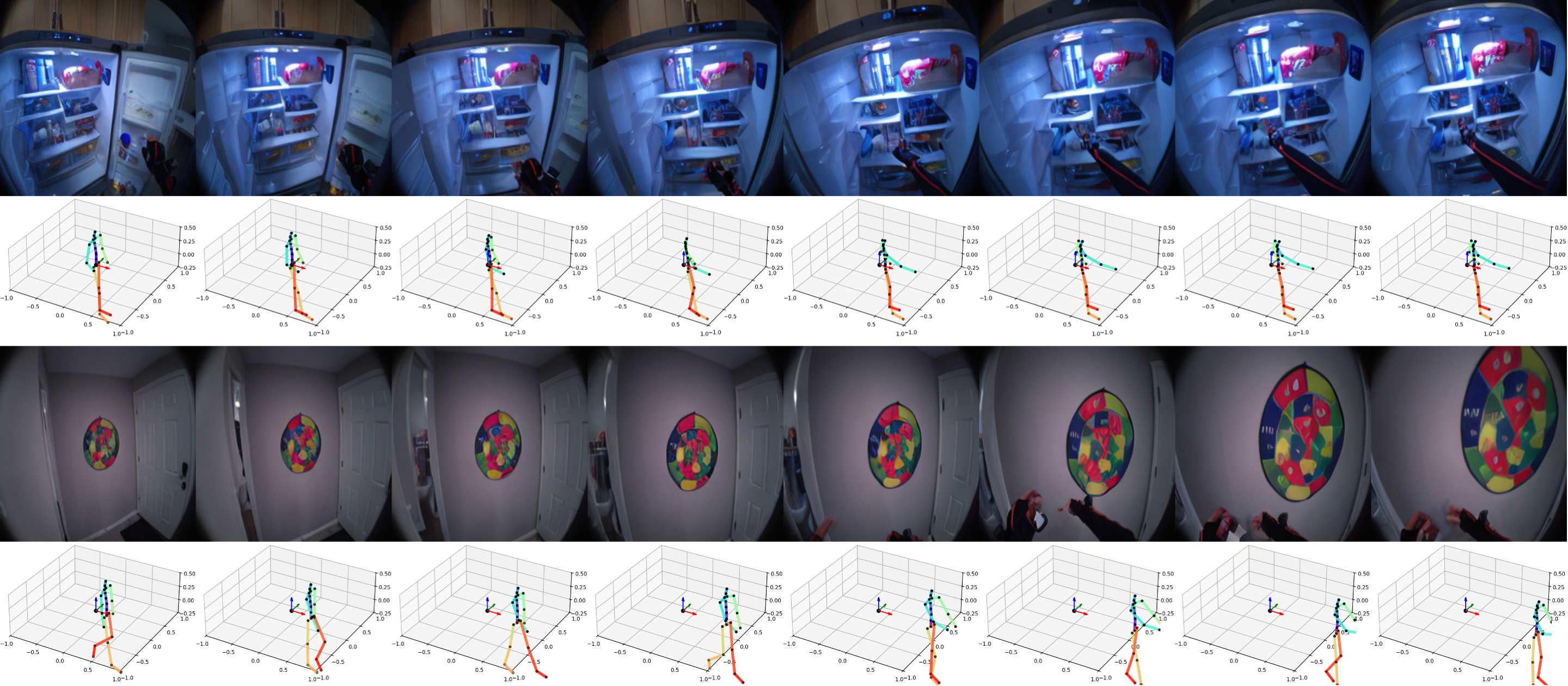 Move Right Hand Left
Move Right Hand Left Move Right Hand Right
Move Right Hand RightMaintaining Coherence in Extended Video Generation
PEVA excels at producing visually and semantically consistent video sequences over long durations. Demonstrations include 16-second rollouts conditioned on full-body motion, showcasing the model’s ability to sustain realistic egocentric perspectives and action consequences over time.

 Sequence 1
Sequence 1 Sequence 2
Sequence 2 Sequence 3
Sequence 3Visual Planning Through Action Simulation
PEVA supports planning by simulating multiple candidate action sequences and evaluating them based on perceptual similarity to a target goal, measured using Learned Perceptual Image Patch Similarity (LPIPS). This enables the model to discard suboptimal paths and identify sequences that achieve desired outcomes.

Example: The model eliminates routes leading to the sink or outdoors, successfully finding the path to open the fridge.

Example: The model avoids paths involving grabbing plants or going to the kitchen, instead finding a plausible sequence to reach the shelf.
Optimizing Action Sequences for Visual Goals
Planning is formulated as an energy minimization problem, solved via the Cross-Entropy Method (CEM). PEVA optimizes sequences of arm movements while keeping other body parts fixed, demonstrating the ability to generate plausible action plans that approach target poses or interactions.

Example: Predicted sequence raises the right arm toward a mixing stick, though left arm adjustments are not modeled.

Example: Sequence reaches toward a kettle but does not fully grasp it, illustrating partial goal achievement.

Example: Predicted actions pull the left arm inward, closely matching the goal pose.
Performance Evaluation
PEVA’s effectiveness is validated through multiple quantitative metrics, demonstrating superior perceptual quality, temporal coherence, and scalability compared to baseline models. The model consistently generates high-fidelity egocentric videos conditioned on whole-body actions.
Comparative Perceptual Metrics
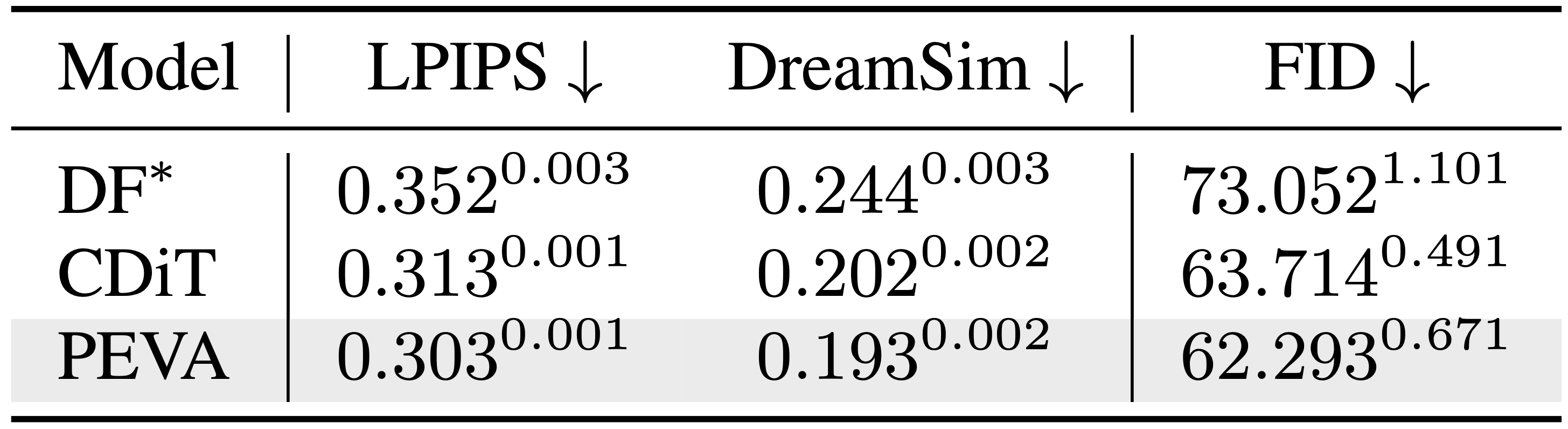
Comparison of perceptual quality metrics across different video prediction models.
Atomic Action Generation Accuracy

Performance comparison on generating videos of atomic actions.
FID Scores Over Time

Fréchet Inception Distance (FID) comparison illustrating video quality degradation over time for various models.
Model Scaling Benefits
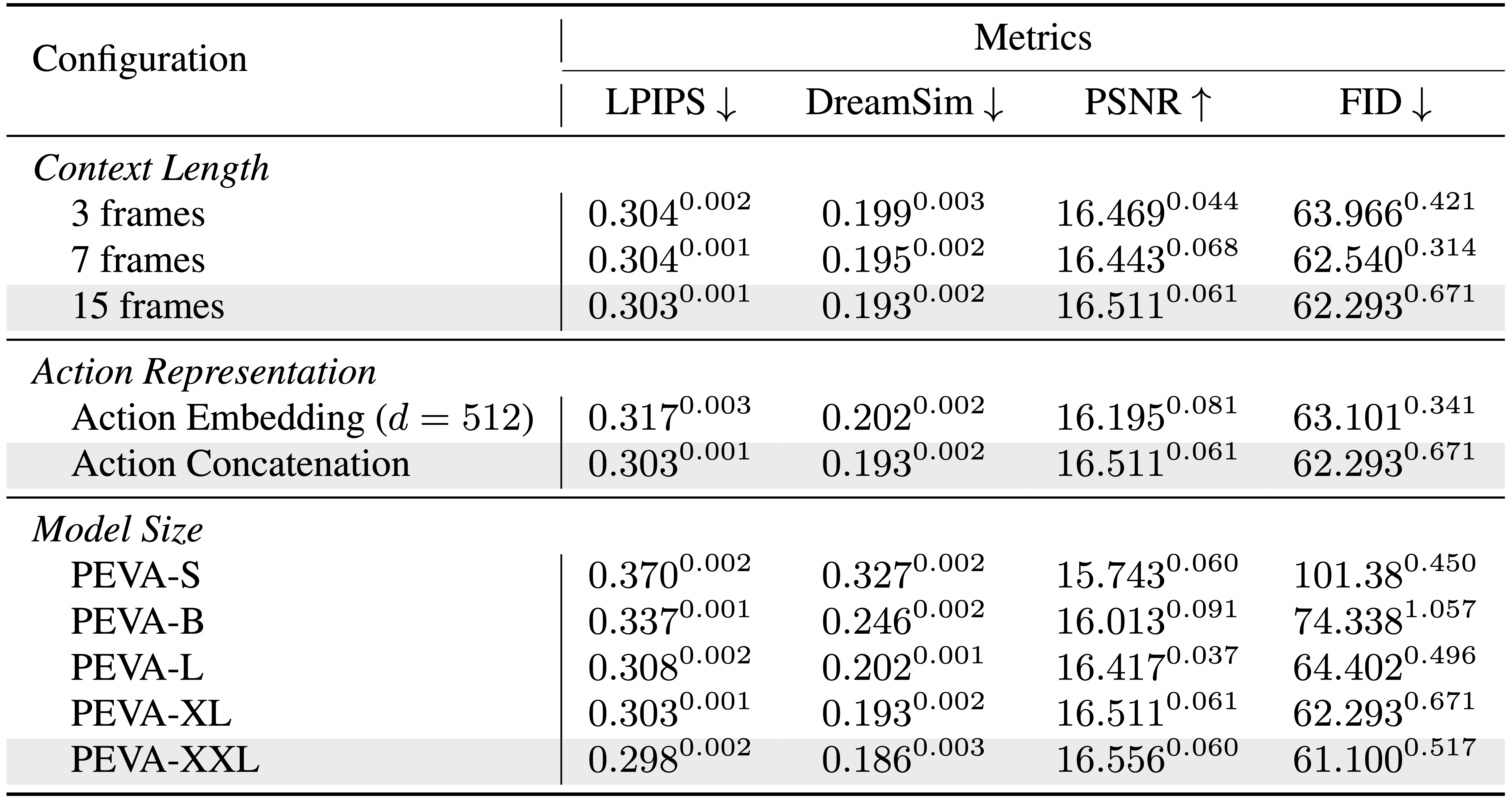
PEVA exhibits improved performance with increased model size, highlighting strong scaling capabilities.
Looking Ahead: Future Enhancements
While PEVA sets a foundation for embodied video prediction and planning, several avenues remain for advancement. Current limitations include restricted planning scope focused on arm actions, absence of long-horizon trajectory optimization, and lack of explicit task or semantic goal conditioning. Future research aims to integrate closed-loop control, interactive environments, and object-centric representations, as well as incorporate high-level goal conditioning to enhance task-directed planning and execution.
