
Mastering Large Language Model Output Control: Essential Parameters and Best Practices
Optimizing the outputs of large language models (LLMs) primarily revolves around fine-tuning the decoding process. This involves manipulating the model’s next-token probability distribution through a set of key parameters. These include max tokens (which limits response length within the model’s context window), temperature (adjusting randomness by scaling logits), top-p (nucleus sampling) and top-k (restricting candidate tokens by rank), frequency penalty and presence penalty (to reduce repetition or encourage diversity), and stop sequences (to enforce precise termination). Understanding how these parameters interplay is crucial for generating coherent, relevant, and cost-effective responses.
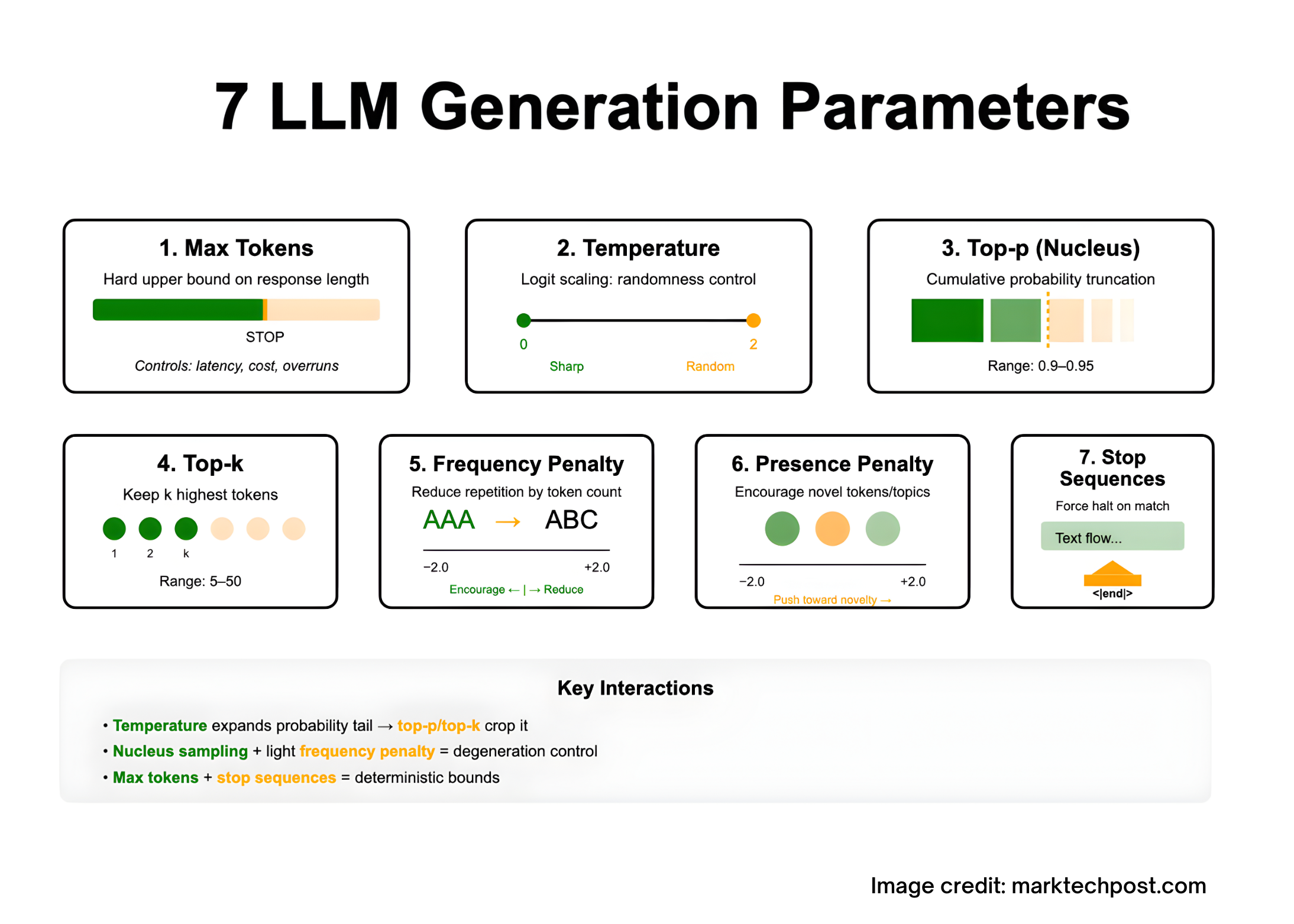
1. Maximum Tokens: Defining Output Length Boundaries
Definition: This parameter sets a strict ceiling on the number of tokens the model can produce in a single output. It does not extend the model’s context window; the combined length of input and output tokens must remain within the model’s maximum context size. If the output reaches this limit, the response is flagged as truncated or incomplete.
When to adjust:
- To manage response latency and API usage costs, since token count correlates directly with both.
- To prevent outputs from exceeding expected boundaries, especially when stop sequences alone are insufficient.
2. Temperature: Balancing Determinism and Creativity
Explanation: Temperature modifies the sharpness of the token probability distribution by scaling logits before applying softmax. Mathematically, the probability of token i is proportional to exp(logit_i / T), where T is the temperature.
Lower temperatures (T < 1) concentrate probability mass on high-likelihood tokens, producing more predictable and focused outputs. Higher temperatures (>1) flatten the distribution, increasing randomness and diversity.
Practical use: Use low temperature for tasks requiring precision and factual accuracy, such as summarization or data extraction. Higher temperature suits creative writing or brainstorming scenarios.
3. Nucleus Sampling (Top-p): Targeted Probability Mass Selection
Concept: Instead of sampling from the entire vocabulary, nucleus sampling restricts choices to the smallest set of tokens whose cumulative probability exceeds a threshold p. This method effectively trims the long tail of unlikely tokens that often cause incoherent or repetitive text.
Recommended settings: For open-ended generation, values between 0.9 and 0.95 are common. It’s generally advised to adjust either temperature or top-p, but not both simultaneously, to maintain controlled randomness.
4. Top-k Sampling: Limiting Candidates by Rank
Definition: At each generation step, top-k sampling confines token selection to the top k most probable tokens, normalizing their probabilities before sampling. This approach enhances output novelty compared to deterministic methods like beam search.
Guidelines: Typical values range from 5 to 50, balancing diversity and coherence. When both top-k and top-p are set, many implementations apply top-k filtering first, followed by top-p filtering.
5. Frequency Penalty: Reducing Redundancy in Long Outputs
Purpose: This parameter lowers the likelihood of tokens based on how frequently they have already appeared in the generated text, discouraging verbatim repetition. Positive values reduce repeated phrases, while negative values can encourage reiteration.
Use cases: Particularly useful in lengthy outputs such as detailed reports, poetry, or code comments where looping or echoing is common.
6. Presence Penalty: Encouraging Novelty and Topic Exploration
Function: Unlike frequency penalty, presence penalty penalizes tokens simply for having appeared at least once, nudging the model to introduce new concepts or vocabulary. Positive values promote diversity, while negative values keep the model focused on existing themes.
Tuning tip: Begin with zero and increase if the model’s responses feel too repetitive or constrained.
7. Stop Sequences: Precise Control Over Output Termination
Definition: Stop sequences are specific strings that, when generated, immediately halt the decoding process without including the stop text in the output. This is essential for structured outputs like JSON or segmented content.
Best practices: Choose unique, unlikely-to-occur delimiters (e.g., "<|endoftext|>" or "###STOP###") and combine with max tokens to ensure robust output boundaries.
Key Parameter Interactions and Optimization Strategies
- Temperature vs. Top-p/Top-k: Increasing temperature broadens the token distribution tail, which top-p and top-k then trim. Adjusting one randomness parameter at a time helps maintain predictable behavior.
- Mitigating Degeneration: Nucleus sampling effectively reduces repetitive or nonsensical outputs by excluding low-probability tokens, especially when paired with a mild frequency penalty during extended generations.
- Cost and Latency Considerations: Max tokens directly influence computational expense and response time. Streaming outputs can improve user experience without increasing cost.
- Model-Specific Variations: Some specialized LLM endpoints may limit or ignore certain parameters like temperature or penalties. Always consult the model’s documentation before applying configurations.

{kind=link}